谁动了GPU的奶酪?
AI市场中现在仍是GPU占主导,那么哪类公司能撼动GPU的地位呢?在当今的AI市场的格局中,主要有四类:有产品,有生态,大批量被部署的,是第一类;有产品,有部分生态,有部分部署的,是第二类;有产品,没有生态,没有客户的,是第三类;没有产品,没有生态,没有客户,有PPT的,是第四类。现在大量公司处于“PPT造芯”的阶段。一个事实是,仅靠模仿显然是无法打败GPU的,一些做与某个领先厂商类似产品的公司,不可能仅仅因为性价比更好,而获得市场突破,最后取得很好地位,这在全球硬科技史上基本很少看到。一个鲜明的例子——计算平台,最开始是大型机,然后小型机,没有说大型机取代大型机的,也没有小型机取代小型机,小型机最后被PC服务器给取代,而如今PC服务器也面临着Arm的挑战。可以看到真正巨头的涌现是因为在产业大的变局、在新浪潮革新当中取得了自己的位置。“在计算机历史上只发生过三次革命,第一次是70年代的CPU,第二次是90年代的GPU,而Graphcore就是第三次革命。”这句话是英国半导体之父、Arm联合创始人Hermann Hauser所说。他所指的正是Graphcore率先提出的就是为AI计算而生的IPU。
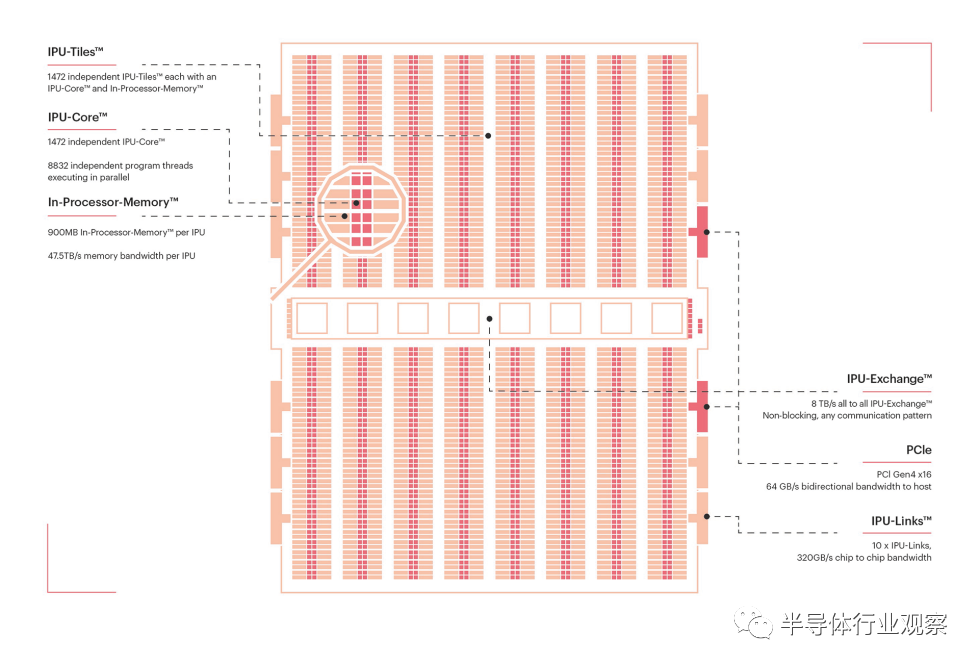
随着应用端需求迅猛飞起,AI模型的尺寸和复杂性正在呈指数级别增长,但是机器智能创新者往往不得不采用传统的处理器架构CPU和GPU,未来需要一款全新的处理器来消除创新的桎梏。这就是IPU。Graphcore通过IPU技术正在全球和中国范围内掀起第三次计算机革命的浪潮,云和数据中心正在被IPU重塑。而一开始,Graphcore就从通用性处理器着手,如今看来,这步棋走得很对。AI覆盖的领域非常多,包括视觉、语言、语音、强化学习等方方面面,今天,AI产业的全球顶会还是一票难求,全球顶级学术会议那么多人投稿,这就意味着AI产业的多可能性,有新的可能性才能讲应用的多样性。正如此,通用性是非常重要的。这个时候如果做一个非常固化的处理器,很可能适应不了新的算法。Graphcore目前处于“云、边、端”的云端,大规模计算的场景里,牵扯到算法的研发,就是所谓的训练。所以IPU现在所处的应用领域对通用性要求更高。就拿Graphcore第二代IPU GC200来说,它的芯片特点就是高性能和高通用性。它拥有594亿个晶体管,并采用最新的台积电7纳米工艺制造,是世界上最精密的处理器。每个第二代IPU具有1472个强大的处理器内核,可运行近9000个独立的并行程序线程。每个IPU在FP16.16和FP16.SR(随机取整)上都拥有史无前例的900MB In-Processor-Memory™和250 teraFLOPS AI计算。GC200支持的FP32计算比其他任何单芯片处理器都要多。那么,Graphcore产品的迭代逻辑和规律是什么?这点Graphcore高级副总裁兼中国区总经理卢涛作了解释,他告诉半导体行业观察记者,Graphcore的第一代产品是PCIe形态的,这个产品被服务器厂商集成到服务器里面去,变成一个IPU的服务器。但在这一过程中Graphcore发现了一些技术和商业上的问题,所以Graphcore在第二代产品的时候,以一个1U的形态来交付。其逻辑就是,首先,从技术上来看,在AI计算中,其实不仅仅要考虑一颗芯片计算能力怎么样,也不仅仅要考虑一台机器计算能力怎么样。整个AI的发展趋势是算法模型的参数规模会从数千万扩展到亿,甚至到万亿,这就需要多颗AI处理器来处理,如果这些处理器集群之间网络构建不好,那么效果将很差,所以Graphcore认为通信技术是至关重要的。Graphcore的第二代产品有三个重大的技术突破:计算、数据、通信。从商业的角度,Graphcore主要是要考虑time-to-market(市场进入时间窗口)。做一颗芯片,要看做什么形态的机器是最快的,stack in就可以做设计了。Graphcore认为这是一个把产品呈现给用户的最快方式。
在AI市场,Graphcore是以挑战者身份出现的,据了解,Graphcore的AI芯片的出货量已达到以万为数量级。“既要做处理器,又要打磨产品,构建生态,还要寻找落地的场景,众所周知,AI落地场景的碎片化和难度,所以这对于一个还不满五年的企业来说非常不容易,也是一个非常好的成绩。”卢涛表示。事实证明,产品有价值,用户看到好处,就没有理由不跟你合作。在卢涛看来,用户无外乎两种逻辑:第一种常规逻辑是我有什么好处,第二有什么问题是我解决不了。而这两类Graphcore都有一些相关进展。譬如说第一种场景,用户已经在使用GPU服务于其业务,而且业务不管是从性能、能力上都被GPU验证过且已经大量部署,这时候用户该开始关注怎样能够优化整体的TCO,即同样的事情是不是能够花同样的钱做得更快或功耗更低,或者花更少的钱达成。这是比较商业化的一些逻辑。像目前非常主流的ResNet、BERT这些模型都是从GPU发明产生的,应用跑得也非常好。但在这些应用里面IPU比GPU表现得更好一点,用户是有一定收益的。第二类,一些用户存在没有被满足的需求。简单的说就是,如果用户想要实现的某个特性无论是在CPU还是GPU都达不到上线的指标,那么这个功能可能就实现不了。以时延为例,如果一个GPU达不到所需的吞吐量,就要堆叠多个GPU,但是这样可能造成中间时延指标达不到。如果用户上线的时延指标是10毫秒左右,用GPU来实现时延是20多毫秒,且怎么优化都达不到上线标准,如果此时在IPU上只有5毫秒的时延,那么此时用户的考量就是,不在乎IPU多少钱,即使比GPU更贵,用户也愿意买单。以上这两种逻辑正体现了IPU的优势和亮点。IPU是很通用的处理器,各种各样的业务都能做。一个新事物的出现,新就新在其能做别人所不能做。IPU跟GPU非常不一样,Graphcore很有信心在GPU做不好的地方比他们做得更好,不是说性能提升一两倍,是能做GPU做不了的事情。而在GPU今天很擅长做的地方,Graphcore也在慢慢证明做得不比GPU差,比如视觉、自然语言处理,甚至比GPU好。但最后要想保持足够的市场竞争力,还有很重要的一点,就是要保持足够好的产品的迭代周期和执行力。因为整个芯片行业生意模式是一场马拉松,要不断的迭代优化,最后才能树立市场地位。所以Graphcore在五年不到的历史进程中,量产了两代产品,某种意义上证明公司在产品迭代上的能力,而且新产品还在努力研发中,去年台积电在一次技术峰会上公开表示,他们在3纳米上在重点跟Graphcore合作。
在生态问题上,GPU花了十几年才构建了如今的生态,那么IPU是不是也得花20年?在卢涛看来,这似乎用不了。今天的时代有所不一样,回顾第一个在GPU表现好的视觉模型MXNet,当时是CUDA在背后的支持。而Graphcore的IPU正在跟TensorFlow、PyTorch,以及百度PaddlePaddle合作,构建这样的框架,这会大大加速Graphcore开拓生态的过程。而就在4月21日,Graphcore与神州数码建立合作伙伴关系,神州数码成为Graphcore中国区总代理。在IT产品分销领域,神州数码占据着首屈一指的地位。通过此次合作,Graphcore可以更快地满足全国各地区的来自不同垂直市场的客户购买需求,使客户能够快速获取IPU系统产品和相关服务。卢涛指出,Graphcore进入中国将近两年的时间,组建了自己团队,打磨头部应用的落地,Graphcore看到了市场对于IPU应用的需求已经到即将爆发的阶段了,这个是很大的驱动力,Graphcore要找一个非常强的合作伙伴,一起来迎接这个井喷和爆发。中国市场毫无疑问是全球领先的AI应用落地的区域,中国有大量的数据,各种各样大型的互联网公司、大型的AI公司、大量的落地场景。另外中国非常擅长把各种各样创新的技术做成一个真正落地的大批量应用,而且其速度也非常快。中国市场对于Graphcore公司来说也有如下几个角度的意义:第一,中国是全球领先的AI应用市场,当然对计算的要求会很高,市场潜力也大。第二,中国更加强调产品的落地、大批量的部署以及快速迭代、快速执行的能力,这对Graphcore也非常有意义。在各种各样场景做快速落地,对于其本身技术栈的打磨以及团队执行力的打磨都是非常有意义的。基于以上,Graphcore对在中国市场的整体表现有非常高的期望的,这可以从Graphcore全球的生意区域划分角度看出来,Graphcore在全球分为三个区域市场,一个中国、一个北美、一个其他。这代表了中国市场在Graphcore全公司版图里的重大意义。卢涛认为整个AI产业已经基本上结束了初期,大量商业场景、应用逻辑已经被证明了确实非常有价值,AI技术即将进入产业大规模的蓬勃发展,并落在各种各样行业应用里。“AI是今天的一个重磅技术,这个合作是非常深远的,未来可能是爆发式的、战略型的合作。”神州数码企业业务集团相关业务负责人湛羽说到。
以上种种,并不意味着Graphcore要把GPU推翻完全取代,Graphcore对市场未来的预期是有三个主要计算平台并存,CPU、GPU、IPU。“今天AI业务是架构在GPU和CPU之上,落地的场景是重叠的,但我们IPU架构非常不一样,期望我们取得阵地之后,未来有一批AI业务是原生在IPU上成长起来的,这些业务可能不适合GPU、CPU,我们就成为了第三种计算平台。”卢涛讲到,“我们创造IPU是希望帮助AI的创新者获得下一个突破。”
*免责声明:以上内容仅供交和流学习之用。如有任何疑问或异议,请留言与我们联系。