喜欢0次
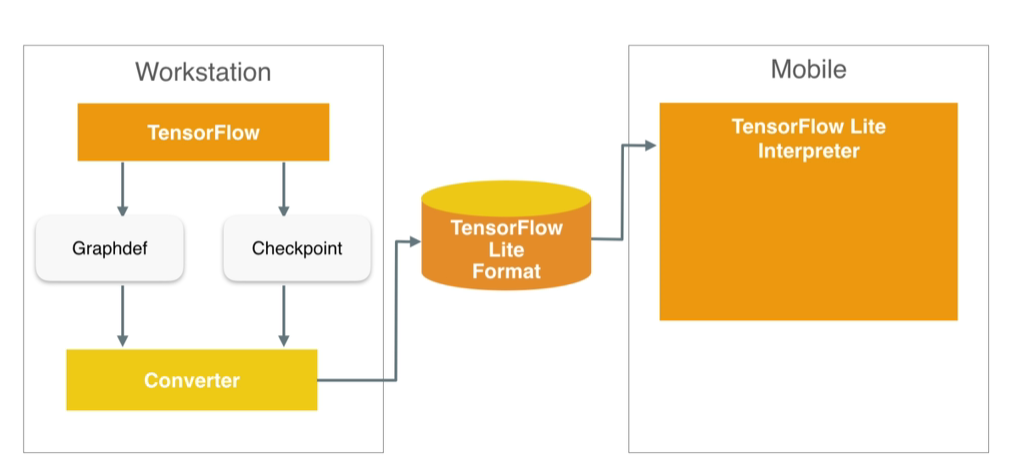
其工作流程如下图(见参考1):
step1: 首先在服务器上使用TensorFLow(或pytorch、keras等)开发模型,训练出权重
step2:使用转换器将模型转换为tflite格式(flatbuffer格式)
step3:在嵌入式设备端(手机、MCU等)加载tflite模型,并执行计算,得到结果。
这篇文章继续分析tflite文件的格式。
TFlite主要由计算图与权重组成。如下图所示:
table Model {
version: uint,
operator_codes: [
...
],
subgraphs: [
tensors: [],
inputs: [],
outputs: [],
operators: [],
],
description: "MLIR Converted.",
buffers: [],
}这个结构对应的图表示如右图。
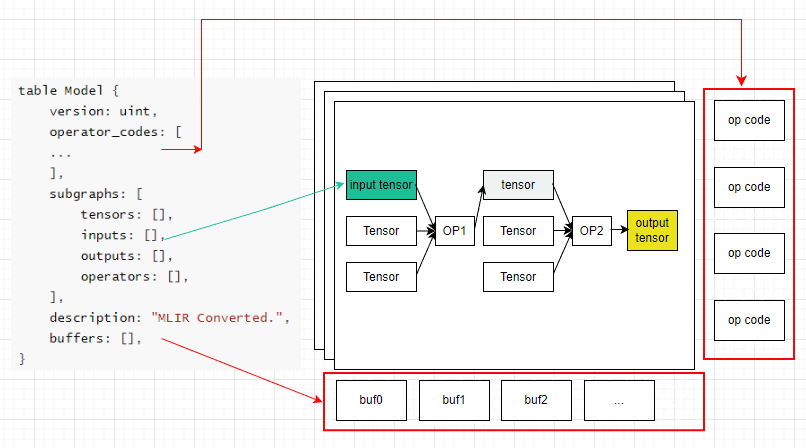
其中:
operator_codes结构体定义了该模型用到的算子。
subgraphs定义了各个子图
buffer定义了数据存储区,计算图中的权重放到buffer中,通过索引来找到对应buffer,
对于subgraphs结构体:
计算图中tensors[]描述了所有的Tensor(包括input/output Tensor)
inputs与outputs指示输入输出的Tensor的id(在tensors[]结构体中的索引值)
operators结构体定义了算子,指出哪些tensor输入,经过什么算子,获得什么tensor输出,这样就可以得到数据流图。
使用flat工具将模型文件解析为json文件,这样可以清楚的看出整个整个数据的流程,参考《tflite格式解析》中的方法2,如下:以mnist_valid_q.tflite为例,用flat命令转化为json文件。
flatc -t schema.fbs -- mnist_valid_q.tflite下面分析,mnist_valid_q.json文件
json的主要结构(略有删节,中间添加部分注释,可与table Model结构体一一对应):
{
version: 3,
/* operator_codes[] 算子索引 */
operator_codes: [
{
deprecated_builtin_code: 3,
version: 3,
builtin_code: "CONV_2D"
},
{
deprecated_builtin_code: 40,
version: 2,
builtin_code: "MEAN"
},
{
deprecated_builtin_code: 9,
version: 4,
builtin_code: "FULLY_CONNECTED"
},
{
deprecated_builtin_code: 25,
version: 2,
builtin_code: "SOFTMAX"
}
],
/* subgraphs[] 各个子图 */
subgraphs: [
{
/* tensors[] */
tensors: [
/* tensor idx = 0 */
{
shape: [
1,
28,
28,
1
],
type: "INT8",
buffer: 1,
name: "ftr0_input",
quantization: {
scale: [
0.003922
],
zero_point: [
-128
]
},
shape_signature: [
-1,
28,
28,
1
]
},
/* tensor idx = 1 */
{
shape: [
2
],
type: "INT32",
buffer: 2,
name: "sequential_1/GAP/Mean/reduction_indices",
quantization: {
}
},
/* tensor idx = 2 */
{
shape: [
4,
3,
3,
1
],
type: "INT8",
buffer: 3,
name: "sequential_1/ftr0/Conv2D",
quantization: {
scale: [
0.012358,
],
zero_point: [
0,
]
}
},
/* tensor idx = 3 */
{
shape: [
4
],
type: "INT32",
buffer: 4,
name: "sequential_1/relu0/Relu;sequential_1/bn0/FusedBatchNormV3;sequential_1/ftr0/BiasAdd/ReadVariableOp/resource;sequential_1/ftr0/BiasAdd;sequential_1/ftr0/Conv2D",
quantization: {
scale: [
0.000048,
],
zero_point: [
0,
]
}
},
/* tensor idx = 4 */
{
shape: [
8,
3,
3,
4
],
type: "INT8",
buffer: 5,
name: "sequential_1/ftr1/Conv2D",
quantization: {
scale: [
0.004238,
],
zero_point: [
0,
]
}
},
/* tensor idx = 5 */
{
shape: [
8
],
type: "INT32",
buffer: 6,
name: "sequential_1/relu1/Relu;sequential_1/bn1/FusedBatchNormV3;sequential_1/ftr1/BiasAdd/ReadVariableOp/resource;sequential_1/ftr1/BiasAdd;sequential_1/ftr1/Conv2D",
quantization: {
scale: [
0.000069,
],
zero_point: [
0,
]
}
},
/* tensor idx = 6 */
{
shape: [
16,
],
type: "INT8",
buffer: 7,
name: "sequential_1/ftr2/Conv2D",
quantization: {
scale: [
0.021189,
],
zero_point: [
0,
]
}
},
/* tensor idx = 7 */
{
shape: [
16
],
type: "INT32",
buffer: 8,
name: "sequential_1/activation/Relu;sequential_1/batch_normalization/FusedBatchNormV3;sequential_1/ftr2/BiasAdd/ReadVariableOp/resource;sequential_1/ftr2/BiasAdd;sequential_1/ftr2/Conv2D",
quantization: {
scale: [
0.000342,
],
zero_point: [
0,
]
}
},
/* tensor idx = 8 */
{
shape: [
10,
16
],
type: "INT8",
buffer: 9,
name: "sequential_1/fc1/MatMul",
quantization: {
scale: [
0.021471
],
zero_point: [
0
]
}
},
/* tensor idx = 9 */
{
shape: [
10
],
type: "INT32",
buffer: 10,
name: "sequential_1/fc1/BiasAdd/ReadVariableOp/resource",
quantization: {
scale: [
0.00048
],
zero_point: [
0
]
}
},
/* tensor idx = 10 */
{
shape: [
1,
13,
13,
4
],
type: "INT8",
buffer: 11,
name: "sequential_1/relu0/Relu;sequential_1/bn0/FusedBatchNormV3;sequential_1/ftr0/BiasAdd/ReadVariableOp/resource;sequential_1/ftr0/BiasAdd;sequential_1/ftr0/Conv2D1",
quantization: {
scale: [
0.016224
],
zero_point: [
-128
]
},
shape_signature: [
-1,
]
},
/* tensor idx = 11 */
{
shape: [
1,
],
type: "INT8",
buffer: 12,
name: "sequential_1/relu1/Relu;sequential_1/bn1/FusedBatchNormV3;sequential_1/ftr1/BiasAdd/ReadVariableOp/resource;sequential_1/ftr1/BiasAdd;sequential_1/ftr1/Conv2D1",
quantization: {
scale: [
0.016134
],
zero_point: [
-128
]
},
shape_signature: [
-1,
]
},
/* tensor idx = 12 */
{
shape: [
1,
2,
2,
16
],
type: "INT8",
buffer: 13,
name: "sequential_1/activation/Relu;sequential_1/batch_normalization/FusedBatchNormV3;sequential_1/ftr2/BiasAdd/ReadVariableOp/resource;sequential_1/ftr2/BiasAdd;sequential_1/ftr2/Conv2D1",
quantization: {
scale: [
0.056649
],
zero_point: [
-128
]
},
shape_signature: [
-1,
]
},
/* tensor idx = 13 */
{
shape: [
1,
16
],
type: "INT8",
buffer: 14,
name: "sequential_1/GAP/Mean",
quantization: {
scale: [
0.022351
],
zero_point: [
-128
]
},
shape_signature: [
-1,
16
]
},
/* tensor idx = 14 */
{
shape: [
1,
10
],
type: "INT8",
buffer: 15,
name: "sequential_1/fc1/MatMul;sequential_1/fc1/BiasAdd",
quantization: {
scale: [
0.151394
],
zero_point: [
42
]
},
shape_signature: [
-1,
10
]
},
/* tensor idx = 15 */
{
shape: [
1,
10
],
type: "INT8",
buffer: 16,
name: "Identity",
quantization: {
scale: [
0.003906
],
zero_point: [
-128
]
},
shape_signature: [
-1,
10
]
}
],
/* inputs tensor id */
inputs: [
0
],
/* outputs tensor id */
outputs: [
15
],
/* operators[] */
operators: [
{
inputs: [
0,
2,
3
],
outputs: [
10
],
builtin_options_type: "Conv2DOptions",
builtin_options: {
padding: "VALID",
stride_w: 2,
stride_h: 2,
fused_activation_function: "RELU"
}
},
{
inputs: [
10,
4,
5
],
outputs: [
11
],
builtin_options_type: "Conv2DOptions",
builtin_options: {
padding: "VALID",
stride_w: 2,
stride_h: 2,
fused_activation_function: "RELU"
}
},
{
inputs: [
11,
6,
7
],
outputs: [
12
],
builtin_options_type: "Conv2DOptions",
builtin_options: {
padding: "VALID",
stride_w: 2,
stride_h: 2,
fused_activation_function: "RELU"
}
},
{
opcode_index: 1, /* 在 operator_codes[] 中找,为mean */
inputs: [
12,
1
],
outputs: [
13
],
builtin_options_type: "ReducerOptions",
builtin_options: {
}
},
{
opcode_index: 2, /* 在 operator_codes[] 中找,为fully_connected */
inputs: [
13,
8,
9
],
outputs: [
14
],
builtin_options_type: "FullyConnectedOptions",
builtin_options: {
}
},
{
opcode_index: 3, /* 在 operator_codes[] 中找,为softmax */
inputs: [
14
],
outputs: [
15
],
builtin_options_type: "SoftmaxOptions",
builtin_options: {
beta: 1.0
}
}
],
name: "main"
}
],
description: "MLIR Converted.",
buffers: [
/* buffer id = 0 */
{
},
/* buffer id = 1 */
{
},
/* buffer id = 2 */
{
data: [
1,
0,
0,
0,
]
},
/* buffer id = 3 */
{
data: [
47,
94,
91,
70,
]
},
/* buffer id = 4 */
{
data: [
20,
254,
255,
255,
]
},
/* buffer id = 5 */
{
data: [
241,
173,
220,
195,
]
},
/* buffer id = 6 */
{
data: [
36,
55,
0,
0,
]
},
/* buffer id = 7 */
{
data: [
251,
223,
14,
1,
]
},
/* buffer id = 8 */
{
data: [
104,
226,
255,
255,
]
},
/* buffer id = 9 */
{
data: [
42,
226,
41,
191,
]
},
/* buffer id = 10 */
{
},
/* buffer id = 11 */
{
},
/* buffer id = 12 */
{
},
/* buffer id = 13 */
{
},
/* buffer id = 14 */
{
},
/* buffer id = 15 */
{
},
/* buffer id = 16 */
{
data: [
49,
46,
49,
52,
]
},
/* buffer id = 17 */
{
data: [
12,
0,
0,
0,
]
}
],
metadata: [
{
name: "min_runtime_version",
buffer: 17
},
{
name: "CONVERSION_METADATA",
buffer: 18
}
],
signature_defs: [
]
}以operators为切入点,可以获取整个计算流图,第一个算子描述如下:
{
inputs: [
0,
2,
3
],
outputs: [
10
],
builtin_options_type: "Conv2DOptions",
builtin_options: {
padding: "VALID",
stride_w: 2,
stride_h: 2,
fused_activation_function: "RELU"
}
},表示:算子的输入为tensor0,tensor2,和tensor3,输出为tensor10,算子为Conv2D,无padding,stride_w与stride_h为2,激活函数为relu
在tensor[]中寻找输入输出测tensor描述。
tensor0描述为:
{
shape: [
1,
28,
28,
1
],
type: "INT8",
buffer: 1,
name: "ftr0_input",
quantization: {
scale: [
0.003922
],
zero_point: [
-128
]
},
shape_signature: [
-1,
28,
28,
1
]
},可见:tensor0的shape为[1, 28, 28, 1],为feature map数据存储位置为buffer1。
tensor2的shape为[4, 3, 3, 1],为卷积kernel
tensor3的shape为[4],为bias
tensor10为输出,shape为:[1, 13, 13, 4]
注意:data中都是以u8呈现,所以如果是其它数据类型的数据,需要将u8拼接一下, 如int32由4个u8拼接解析得到
依次推导下来,我们可以获得如下的计算流图:
(下图参考《tflite格式解析》中的方法4生成)
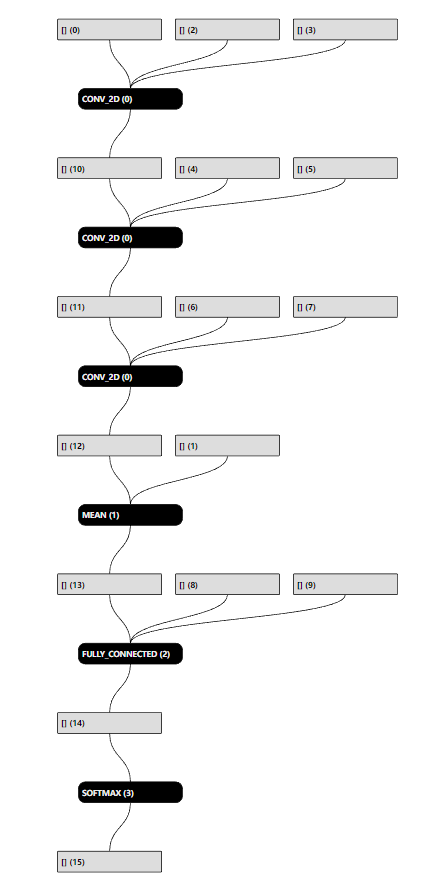
参考: