喜欢1次
使用了自己的FPGA开发板,通过普通的IO实现jtag调试器连接,FPGA顶层的引脚如下图所示

其中qspi引脚用的是FPGA固化程序用的flash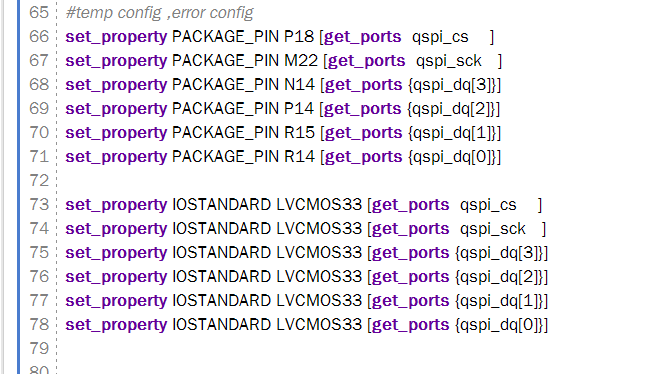
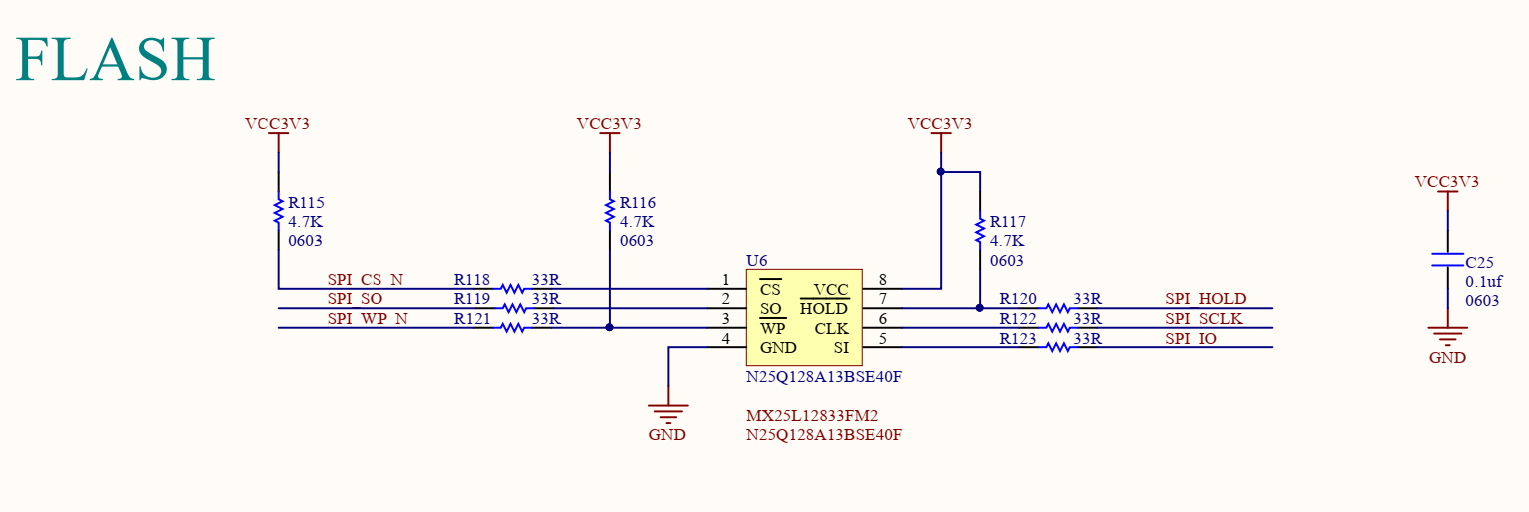
而下载器则是通过淘宝上购买的一个sispeed USB转JTAG+UART的下载器
然后在nuclei studio上选择的是sdk-hbird_sdk @0.1.3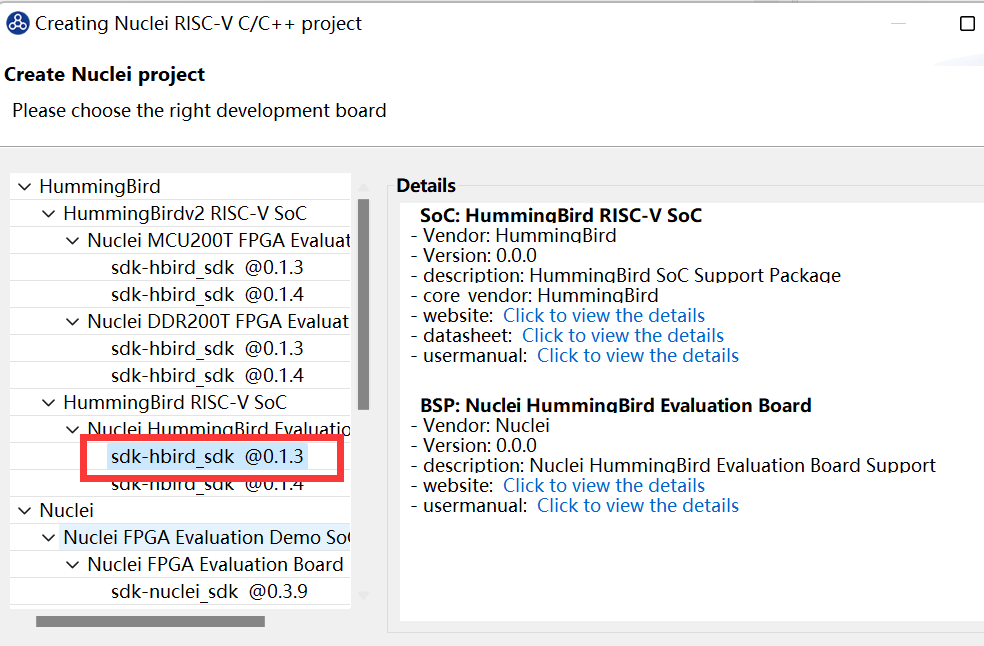
在点击debug 按钮时总是会有各种报错,总是不能成功,试了无数次后只成功过一次半,其他均失败。而且每次报错信息还不一样
按钮时总是会有各种报错,总是不能成功,试了无数次后只成功过一次半,其他均失败。而且每次报错信息还不一样
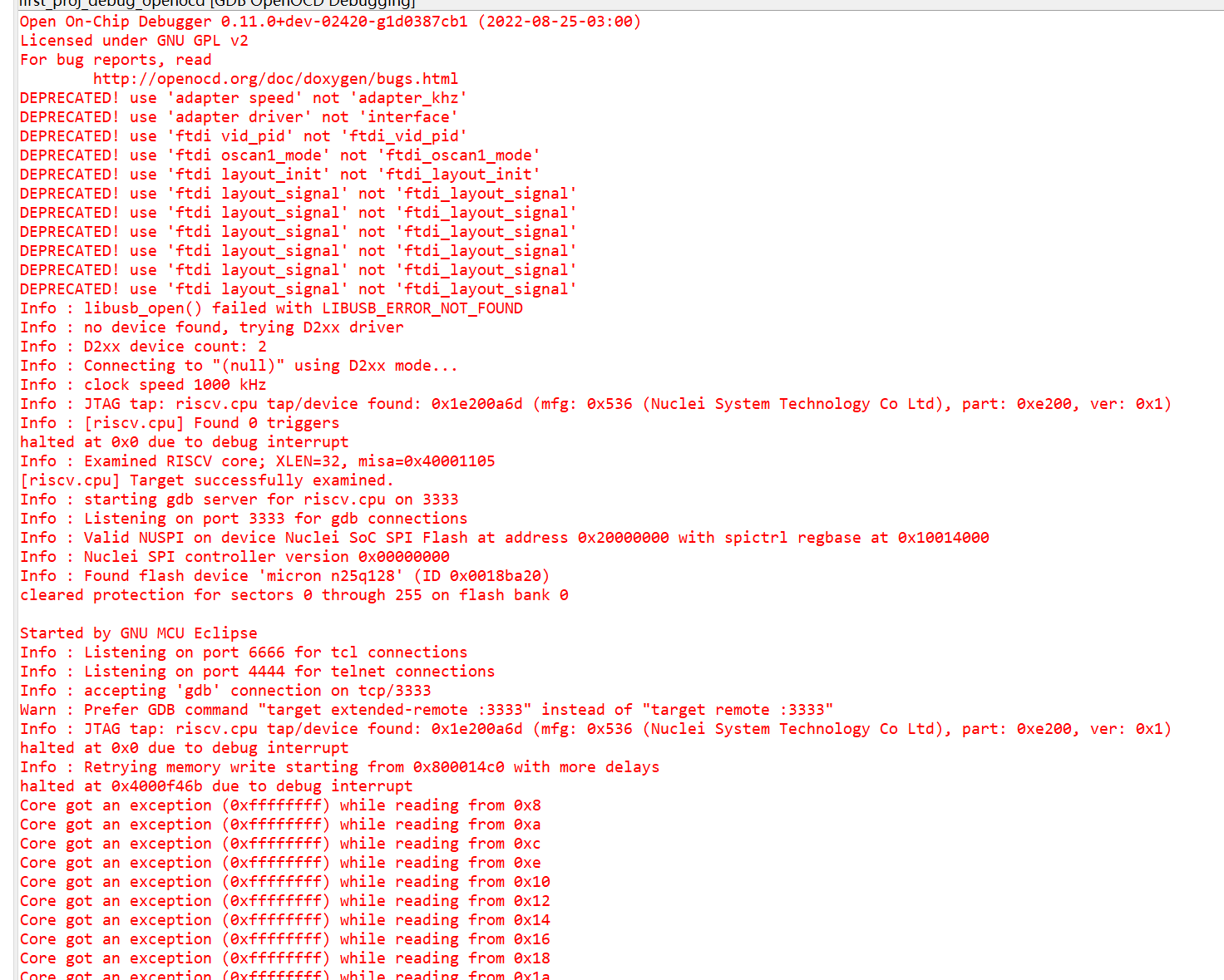
下面是各种报错信息

 ![图片alt]
![图片alt]
下面两张图是成功的那次的报错信息,是经过无数debug,然后某次串口突然停止输出了(平时一般一直输出0),然后按下mcu复位按键,就实现了下载成功,但也只成功过这一次
(/uploadfile/editor/0/3/3743.png)
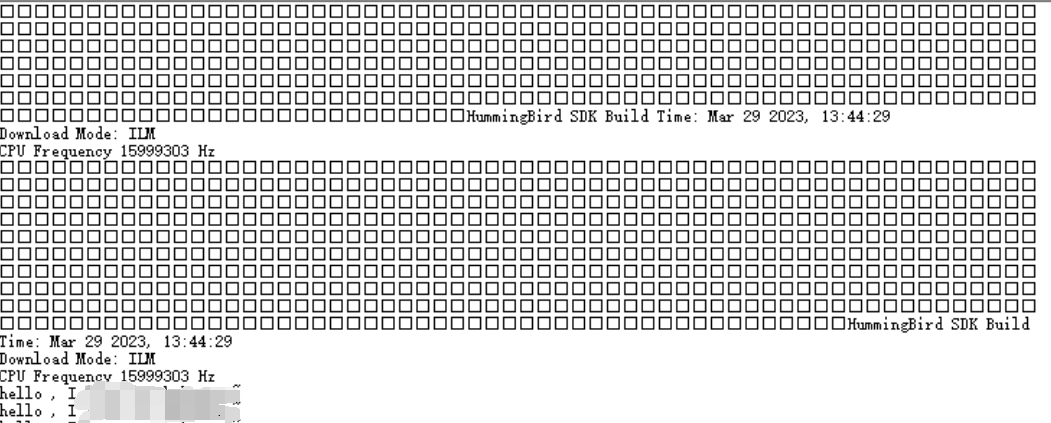
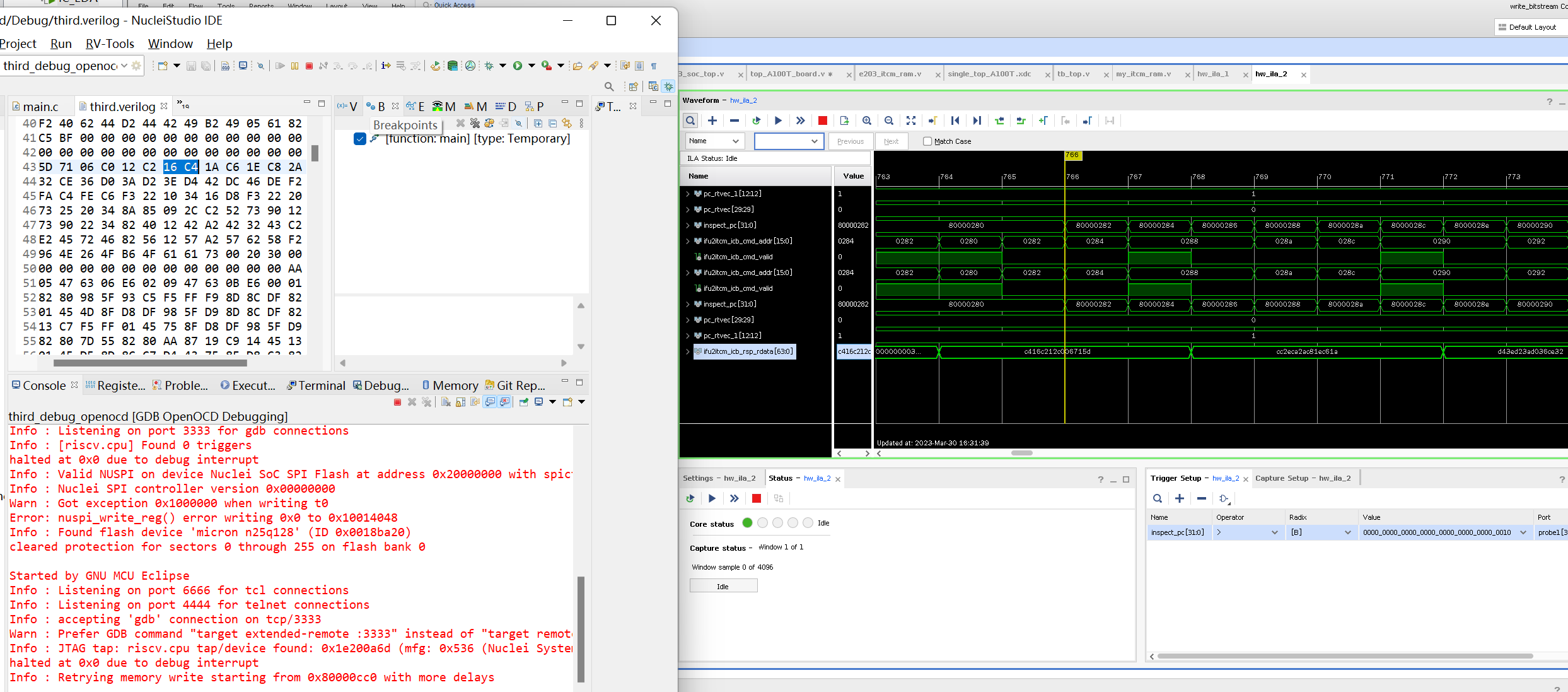
另外通过debug,在烧写FPGA程序时候,观察一下信号,inspect_pc一直处于0和2,然后nuclei studio下载后指令变化了,FPGA上观察到的指令值对比了一下.verilog文件的指令值是一样的,说明还是有程序写进去了,但是还是一直报错,串口也无法输出打印的信息
DEPRECATED! use ‘adapter speed’ not ‘adapter_khz’
DEPRECATED! use ‘adapter driver’ not ‘interface’
DEPRECATED! use ‘ftdi vid_pid’ not ‘ftdi_vid_pid’
DEPRECATED! use ‘ftdi oscan1_mode’ not ‘ftdi_oscan1_mode’
DEPRECATED! use ‘ftdi layout_init’ not ‘ftdi_layout_init’
DEPRECATED! use ‘ftdi layout_signal’ not ‘ftdi_layout_signal’
DEPRECATED! use ‘ftdi layout_signal’ not ‘ftdi_layout_signal’
DEPRECATED! use ‘ftdi layout_signal’ not ‘ftdi_layout_signal’
DEPRECATED! use ‘ftdi layout_signal’ not ‘ftdi_layout_signal’
DEPRECATED! use ‘ftdi layout_signal’ not ‘ftdi_layout_signal’
DEPRECATED! use ‘ftdi layout_signal’ not ‘ftdi_layout_signal’
Info : libusb_open() failed with LIBUSB_ERROR_NOT_FOUND
Info : no device found, trying D2xx driver
Info : D2xx device count: 2
Info : Connecting to “(null)” using D2xx mode…
Info : clock speed 1000 kHz
Info : JTAG tap: riscv.cpu tap/device found: 0x1e200a6d (mfg: 0x536 (Nuclei System Technology Co Ltd), part: 0xe200, ver: 0x1)
Info : Examined RISCV core; XLEN=32, misa=0x40001105
[riscv.cpu] Target successfully examined.
Info : starting gdb server for riscv.cpu on 3333
Info : Listening on port 3333 for gdb connections
Info : [riscv.cpu] Found 0 triggers
halted at 0x0 due to debug interrupt
Info : Valid NUSPI on device Nuclei SoC SPI Flash at address 0x20000000 with spictrl regbase at 0x10014000
Info : Nuclei SPI controller version 0x00000000
Warn : Got exception 0x1000000 when writing t0
Error: nuspi_write_reg() error writing 0x0 to 0x10014048
Info : Found flash device ‘micron n25q128’ (ID 0x0018ba20)
cleared protection for sectors 0 through 255 on flash bank 0
Started by GNU MCU Eclipse
Info : Listening on port 6666 for tcl connections
Info : Listening on port 4444 for telnet connections
Info : accepting ‘gdb’ connection on tcp/3333
Warn : Prefer GDB command “target extended-remote :3333” instead of “target remote :3333”
Info : JTAG tap: riscv.cpu tap/device found: 0x1e200a6d (mfg: 0x536 (Nuclei System Technology Co Ltd), part: 0xe200, ver: 0x1)
halted at 0x0 due to debug interrupt
Info : Retrying memory write starting from 0x80000cc0 with more delays
halted at 0x80000280 due to debug interrupt
Warn : Got exception 0x10 when reading mstatus
Error: Failed to read mstatus register.
Info : dropped ‘gdb’ connection