喜欢0次
AES加密模式中,有一种CTR模式,其流程如下图:
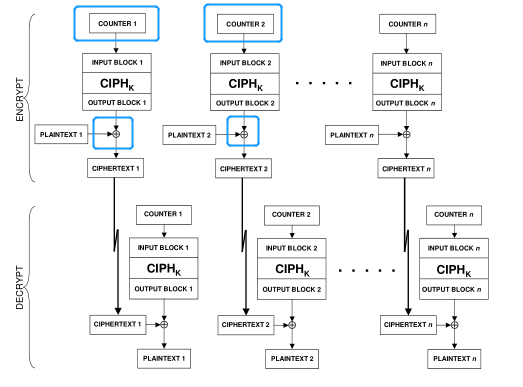
加密时,除了明文和密钥外,还需要一个初始向量COUNTER1,将其加密的结果和明文异或,即可得到密文;下一块明文加密时,COUNTER1加1得到COUNTER2。详情可以查看博文AES的五种加密模式。
以下是我用拓展指令集在AES加速的CTR模式代码,测试的了三块数据,初始向量vi=“0102030405060708”(128bit),但编译之后,加密的结果只有第一块正确,其余两块不正确,vivado查看波形,发现三次的COUNTER没有改变,但最后COUNTER的结果确实加了3,到底是为什么?
int NICE_aesEncrypt_ctr(const uint8_t *key, uint32_t keyLen, const uint8_t *vi,
const uint8_t *pt, uint8_t *ct, uint32_t len)
{
//拷贝初始向量
uint8_t *counter =(char*)malloc(sizeof(char)*16);
memcpy(counter, vi, keyLen);
uint8_t *pos = ct;
for(int i=0; i<len; i+=BLOCKSIZE){
NICE_loadkey((int)key); //加载密钥
NICE_loadstate((int)counter); //加载counter
NICE_encrypt(); //加密
NICE_xorvi((int)pt); //明文异或
NICE_storestate((int)pos); //保存密文
pos +=BLOCKSIZE; //下一个密文位置
pt +=BLOCKSIZE; //下一个明文位置
counter[15]+= 1; //计数器加1
}
return 0;
}
代码编译的时候,我采用的是-O2或-O3,在编译器看来,代码中NICE_loadstate((int)counter)①和counter[15]+= 1②的counter似乎没有数据冲突,因此编译器做循环展开优化的时候,会分开独立运行这两条指令,所以三块的输入向量没有依次累加,但最后counter连续加了3下。以三个数据块为例,原本的执行顺序是①②①②①②,编译优化后的顺序是①①①②②②,这样得到的结果显然不对。
那么如何让编译器“笨”一些呢,我首先采用的是不加优化,结果确实按顺序累加,结果正确。但总觉得不太爽,毕竟-O2优化非常常用,这里不用,其他地方也得用,不加优化不是长远之计。
既然编译器认为数据不相关,那么能不能加些东西,让它数据相关,于是借助循环变量i,做累加操作,但结果还是不对。
一觉醒来,突然想到内联汇编,决定一试:既然编译器不能如我所愿,那可以把想要的部分先自己编译。各种架构在线编译平台
稍微做一些调整,将+1的操作移到前面,不然要写好多汇编...
int NICE_aesEncrypt_ctr(const uint8_t *key, uint32_t keyLen, const uint8_t *vi,
const uint8_t *pt, uint8_t *ct, uint32_t len)
{ //拷贝初始向量
uint8_t *counter =(char*)malloc(sizeof(char)*16);
memcpy(counter, vi, keyLen);
uint8_t *pos = ct;
int zero=0;
counter[15]-=1; //预先处理
for(int i=0; i<len; i+=BLOCKSIZE){
NICE_loadkey((int)key);
__asm__ __volatile__(
" lb x10,15(%[src1]) \n\t" //以下三条完成+1操作
" addi x10,x10,1 \n\t"
" sb x10,15(%[src1]) \n\t"
" .insn r 0x7b,2,0x12,x0,%[src1],x0 \n\t" //加载counter
:"=r"(zero)
:[src1]"r"(counter)
);
NICE_encrypt();
NICE_xorvi((int)pt);
NICE_storestate((int)pos);
pos +=BLOCKSIZE;
pt +=BLOCKSIZE;
}
return 0;
}内联汇编可以自行决定指令执行的顺序,这在软硬件协同设计里面一定会经常用到。