喜欢2次
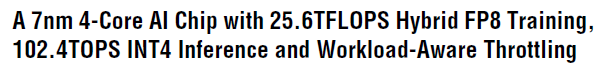
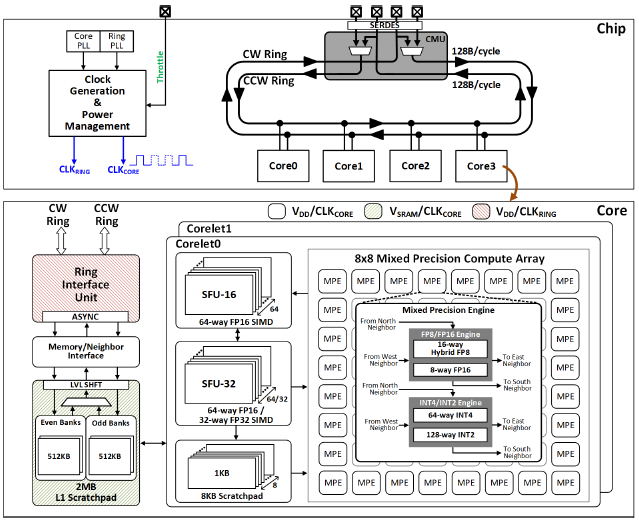
这次要分享的是 IBM 推出的高能效AI训练加速器,特点如下:
1. 支持数据精度:DL Float16,hybrid-fp8,int4,int2
2. 两个双向环形总线 ring bus,片内成环,或者片间成环(众核结构),接口使用 SERDES
3. core, ring bus,异步双PLL,平衡计算和数据搬运的性能 & 功耗
4. 每个core有两个corelet,共享 2MB L1,8*8 PE 阵列,SFU 特殊功能单元,4个数据格式对应2个单元,FPU训练,INT推理
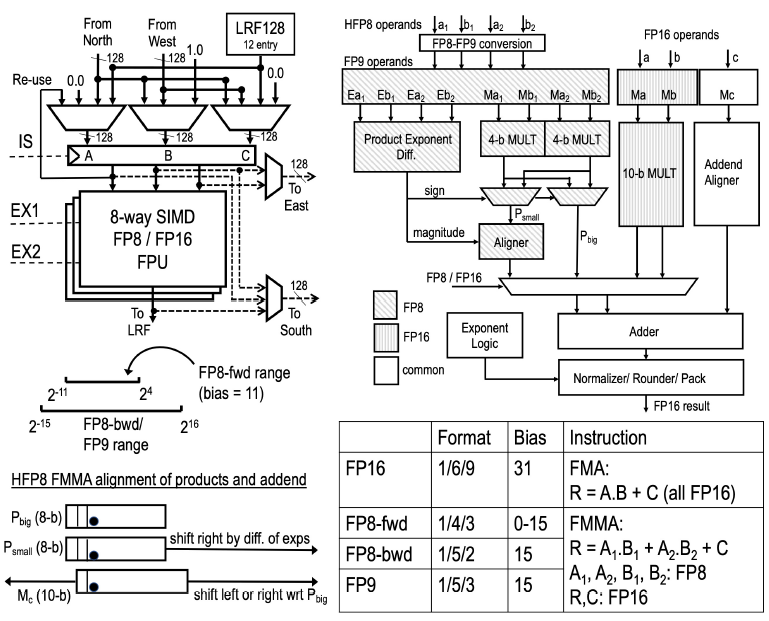
这部分是FPU结构与原理,特点如下:
1. 128bit 总线,通过 MUX 实现前向和反向灵活的数据流
2. hybrid-fp8,正向精度高动态低,反向精度低动态高
3. 独立的 Int infer PE,256bit 总线,booth乘法器
4. PE 使用 Latch
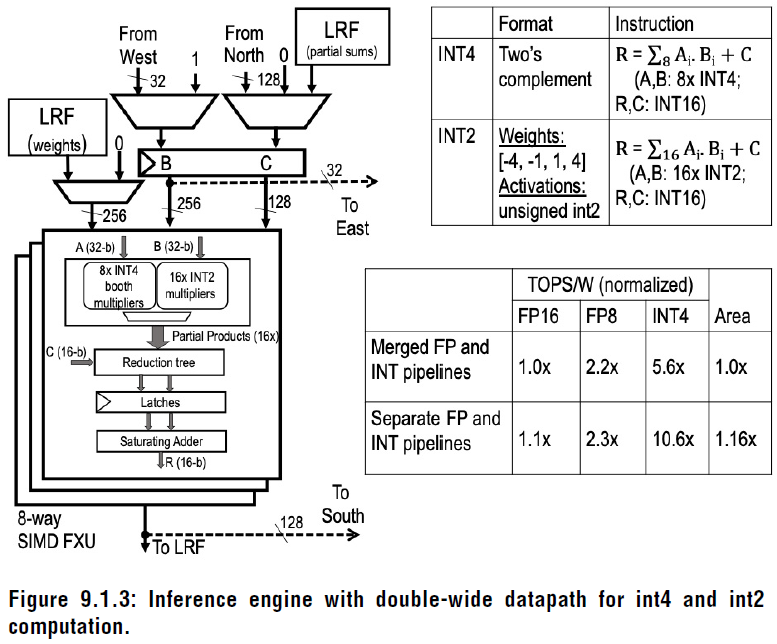
这部分是整数单元
论文使用了 混合精度进行正向推理和反向计算,具体原理如下:
 特点:
特点:
1. 正向和反向使用不同的 FP8,着实有才!

最后一个创新点:预知负载的电压频率调节!
通过软件得到每一层的功耗,确定功耗预算,进行VF调节
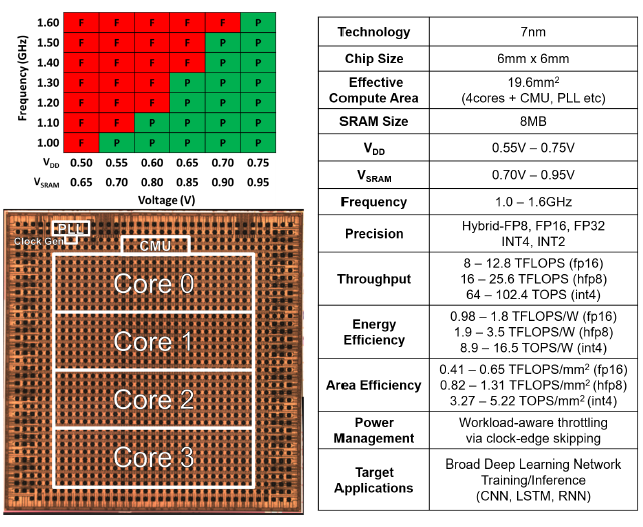
最后是加速器性能数据:
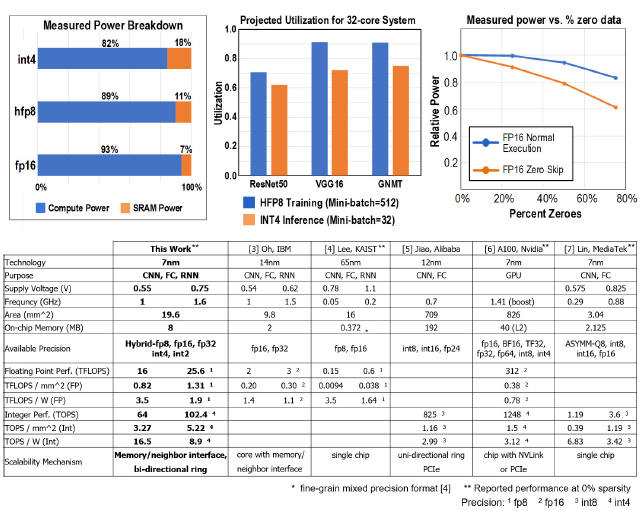
- 0 稀疏度进行测试
- 3种格式,两个电压,给出算力、能效、计算密度
- 低数据精度,SRAM 功耗增加
- 给出了 8 个芯片并行的 PE 利用率,负载 ResNet50, VGG16, GNMT
- 稀疏度和功耗曲线,对比有无 0 跳过逻辑
- 原文多次强调精度较高,可比拟 Float32
【声明】
由 CICC2840 队伍提供的分享,内容和图片来自ISSCC会议。