2025年7月,上海 —— 随着人工智能从云端加速走向终端,边缘智能的需求日益增长。今日,芯来科技 (Nuclei System Technology) 正式发布其全新一代端侧AI加速器IP产品 —— NACC (Nuclei Neural-Network Accelerator) ,该产品面向RISC-V生态的AI计算需求,具备高能效、高并行性与高度可扩展的矩阵计算能力,并提供完整的软件栈适配,致力于打造下一代智能终端的AI计算核心。
端侧AI快速发展,Micro-NPU成关键引擎
人工智能正加速从云端走向终端,广泛融入工业、医疗、汽车、消费电子等领域。相比云端,端侧AI的最大优势在于具备强大的本地实时处理与决策能力,无需依赖网络连接即可完成高效响应,保障系统稳定性与使用连续性,同时在隐私保护和数据安全方面也具有天然优势。这对AI芯片在算力、功耗、集成度和灵活性上提出了更高要求。
在这一背景下,微型神经网络处理器 (Micro-NPU) 成为端侧AI部署的关键引擎,它具备:
高能效比,可在低功耗下完成复杂AI推理任务;
高并行吞吐能力,适配多任务并发执行需求;
本地执行AI推理,无需上传敏感数据至云端,强化隐私与安全保障;
开发门槛低、部署灵活,加快AI创新应用落地节奏;
成本低,以芯片上有限的硬件资源支撑高能效的算力。
基于上述原因,可以预见未来Micro-NPU将成为MCU、AIoT等场景芯片的标配,芯来的Micro-NPU——NACC正是顺应这一趋势而推出,聚焦“端侧智能”应用场景,以更高的AI算力、更低的功耗和更成熟的软件生态,帮助客户构建更强大、更高效的智能终端产品。
全新NACC发布,提供高性能可扩展AI加速能力
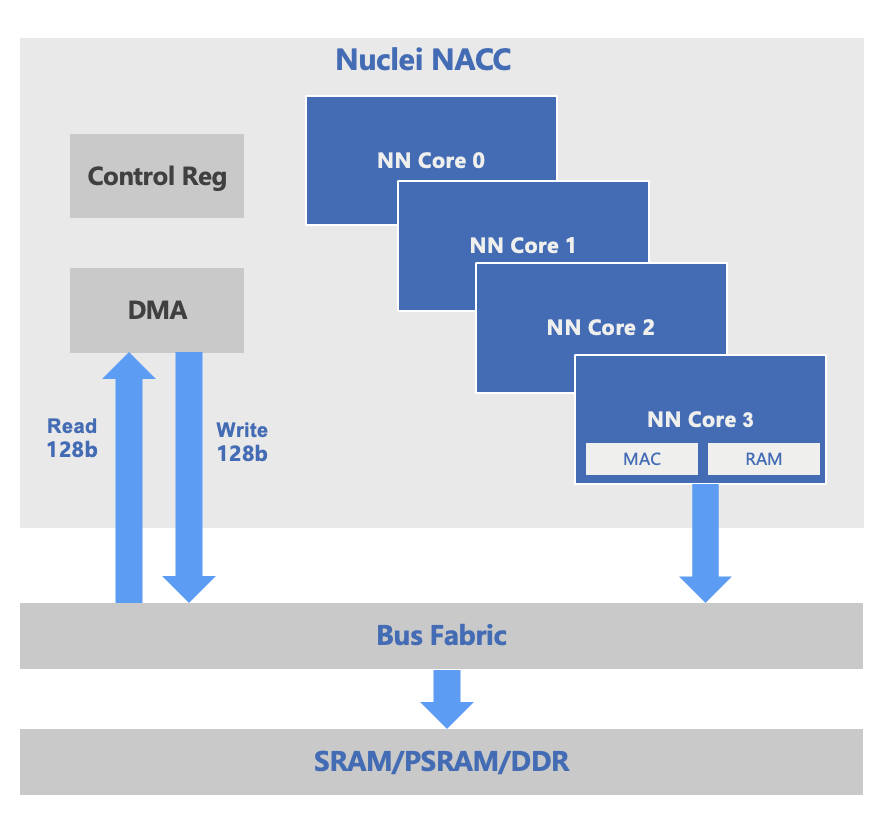
NACC是芯来科技推出的全新Micro-NPU IP,专为RISC-V架构下的端侧智能场景设计,具备以下关键特性:
支持int8与int16的数据类型;
支持1~32核NN Core架构,每核配备64个MAC运算单元;
在T22工艺下运行频率可达1GHz,峰值算力最高配置可达4TOPS;
内置DMA控制器与总线互联结构,支持128-bit或512-bit宽度数据读写,适配SRAM/PSRAM/DDR等存储介质;
提供完整的软硬件协同能力,与芯来全系列RISC-V CPU深度耦合,覆盖N/U/NX/UX等处理器;
与RISC-V CPU协同处理串行逻辑、数据预处理、控制调度等任务,实现AI加速与通用计算的互补协同;
针对使用频繁的算子进行了深度的优化;
提供完整的NN、DSP、AI算法库,支持TFLM、TinyMaix、MCUNet等推理框架;
可部署典型AI模型,如人脸识别、语音识别、手势识别、动作检测等。
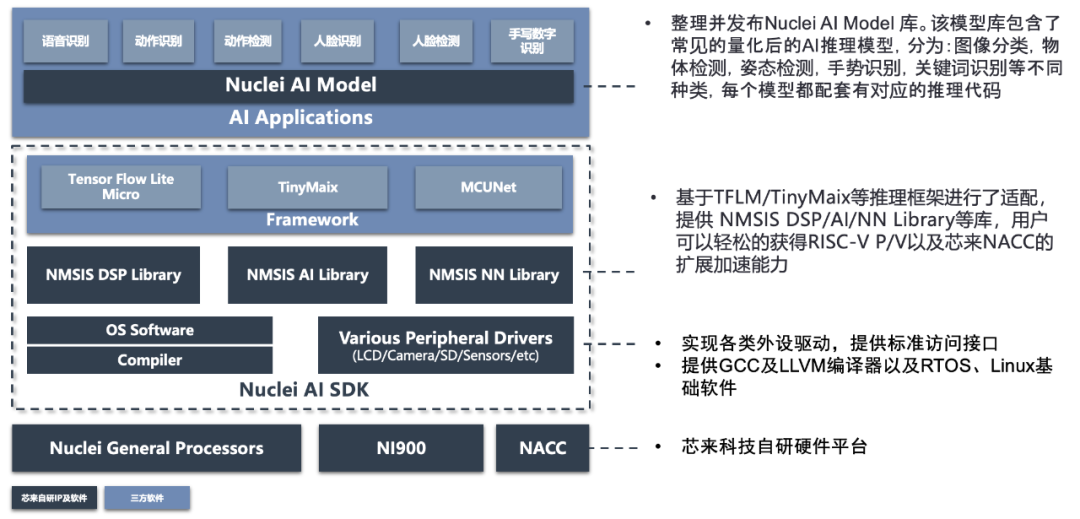
全栈AI软件平台,降低端侧AI开发门槛
为了帮助开发者更高效地构建端侧AI应用,芯来科技围绕NACC构建了覆盖从模型到部署的完整AI软件平台,极大降低AI芯片开发门槛,加速产品化进程。
该平台包括:
Nuclei AI Model库:
集成丰富的量化AI推理模型,覆盖图像分类、物体检测、手势识别、关键字识别、人脸检测等常见AI任务,每个模型均配套对应的推理代码,便于快速集成应用。
轻量级推理框架适配:
平台已完成TensorFlow Lite Micro (TFLM) 、TinyMaix、MCUNet等主流嵌入式AI框架的适配,支持在RISC-V架构上快速部署。
NMSIS软件库集成:
提供优化后的NMSIS DSP、AI、NN等功能库,用户可轻松获得RISC-V P/V扩展与NACC协处理器的硬件加速能力。
全面的底层软件支持:
涵盖GCC/LLVM编译器、RTOS/Linux基础软件以及各类外设驱动 (LCD、摄像头、SD卡、传感器等) ,通过标准接口实现高效集成。
统一AI SDK体系:
将上述所有组件整合为Nuclei AI SDK,并配合芯来自研CPU及NACC平台,为AI开发者提供端到端的完整工具链支持。
该平台不仅实现了软硬协同优化,还提供了稳定、统一的开发环境,使客户能够快速完成AI应用的开发、调试与部署,推动AI功能在RISC-V架构下的广泛落地。
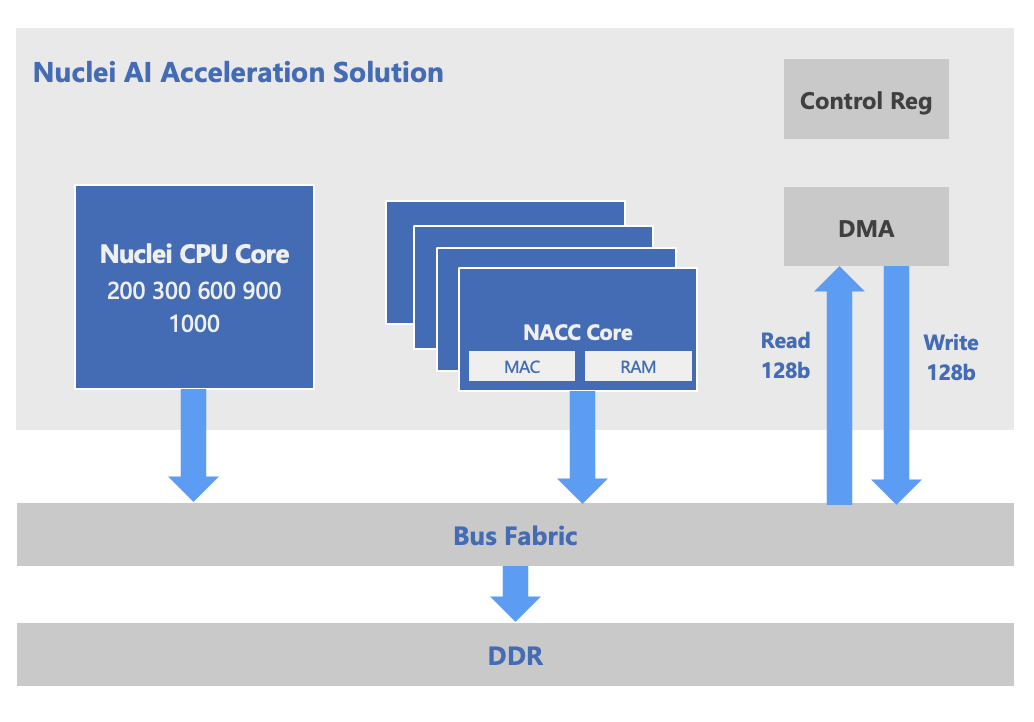
高度耦合CPU子系统,助力AI+通用计算融合
芯来NACC可与芯来自研RISC-V处理器构成紧耦合的异构计算子系统,通过协同DMA、总线、图像IP等模块,帮助客户构建完整的AI子系统平台。其优势包括:
高度协同性和互补性:
数据预处理、串行计算或特殊函数计算可以通过芯来基于RISC-V CPU内核的DSP、Vector扩展来处理,提供更好的性能和更低的功耗;需要并行计算的AI处理任务则可以分配给NACC,从而在大量的AI应用中获得最有效的平衡。
更为统一的软件栈:
芯来科技提供的全套AI软件栈,包括AI框架、软件优化库(DSP、NN、AI)等,整体统一的软件系统更为简便,可以高效的进行资源分配和任务调度。
丰富的可定制化:
不同的AI应用可能需要不同的处理能力和特性,客户可以根据自己的需求自由选择芯来的处理器以及NACC特性,通过高度可配置的RISC-V处理器和NACC的配合,开发者可以优化AI算法的执行效率。
整体子系统整合优化:
芯来提供整体子系统服务,帮助客户快速整合CPU+NACC+DMA+总线+外设IP等,使整体系统更为优化,加速产品研发周期,减少客户资源消耗。
NACC早在2024年便已完成原型验证,目前已在多位客户项目中实现落地,应用于边缘AI传感器、智能网表等智能感知场景,展现出良好的端侧推理加速能力。
高面向未来,打造RISC-V AI算力核心
AI计算正从中心走向边缘,RISC-V在开放性与可扩展性上的优势,使其成为AI芯片的理想基础架构。根据市场预测,到2030年基于RISC-V的AI SoC市场将超过420亿美元,年复合增长率达49.2%。NACC的推出,正是芯来科技积极布局RISC-V AI算力赛道的重要体现。
芯来科技将持续推进RISC-V+AI融合技术的发展,为客户提供可持续演进的AI计算解决方案,加速智能终端的落地与普及。