喜欢1次
编译模型时需要如下两个参数:
一个“损失函数”(loss function),用来衡量网络的预测有多好。
一个“优化器”(optimizer),可以告诉网络如何改变其权重。
keras内置了7个常用的优化器(keras.optimizers),如下:
| 优化器 | 说明 |
|---|---|
| SGD (随机梯度下降优化) | keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False) |
| Adagrad (自适应梯度下降算法) | keras.optimizers.Adagrad(lr=0.01, epsilon=None, decay=0.0) |
| Adadelta (自适应学习速率算法) | keras.optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=None, decay=0.0) |
| RMSprop(均方差传播算法) | keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0) |
| Adam(自适应动量估计) | keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False) |
| Adamax(自适应最大阶动量估计) | keras.optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0) |
| Nadam(Nesterov加速自适应动量估计) | keras.optimizers.Nadam(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, schedule_decay=0.004) |
上述优化器可以分为两类:1 梯度下降算法类 2 自适应学习率类。这些算法的基础都是梯度下降算法,只是在梯度下降算法的基础上做了一些优化。
包括基础的梯度下降算法、批量梯度下降法,随机梯度下降,小批量梯度下降法。它们的学习率是固定的。
顾名思义,梯度下降法的计算过程就是沿梯度下降的方向求解极小值(使得损失函数最小,也即准确率最高)。
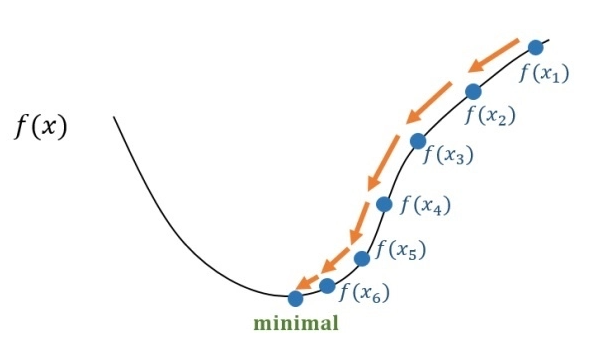
假设losses函数为f(x),如上图所示(图片来源于网络,侵删),我们的目的是使losses最小的点(这时候模型准确率最高),怎么寻找呢?
方法1:遍历法
选取某一步长,从左到右遍历求取所有点的函数值,然后比较大小。(优点:准确,不会陷入局部最小值,缺点:计算量太大,难以接受)
方法2:梯度下降算法
梯度下降的基本公式为:新值 = 旧值 - 学习率 * 偏导数,当偏导数越大,表示越陡峭,在此处下降得比较快,梯度下降算法的核心就是利用目标函数的偏导信息(梯度)来指导下一步的移动方向和步长, 因此,梯度下降法也被称为最速下降法。
学习率也即步长是很重要的一个参数,如果学习率太小,需要经过多次迭代,算法才能收敛,这是非常耗时的。如果学习率太大,可能跳过最低点,甚至函数值越来越大(发散),这就有了针对学习率的改进的各类算法。
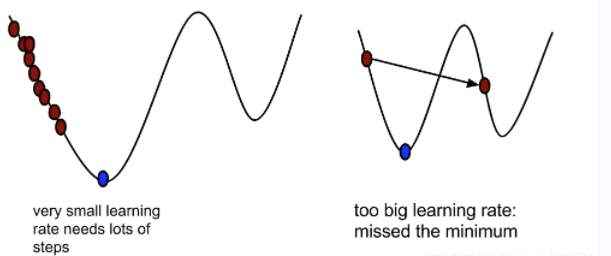
批量梯度下降法是最基本的梯度下降法,它使用整个训练集来计算梯度并更新模型参数。由于需要计算所有样本的梯度,批量梯度下降法的计算复杂度较高,但通常能够保证收敛到全局最优解。
代码示例:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad随机梯度下降法在每次迭代中只使用一个样本来计算梯度,并更新模型参数。由于每次只计算一个样本的梯度,随机梯度下降法的计算复杂度较低,但可能会出现收敛到局部最优解的情况。
示例代码:
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad小批量梯度下降法则是批量梯度下降法和随机梯度下降法的折中方案,它在每次迭代中使用一小部分样本来计算梯度,并更新模型参数。小批量梯度下降法通常比批量梯度下降法更快收敛,同时也能够避免随机梯度下降法的一些缺点。
代码示例:
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad梯度下降算法需要选择固定的学习率,但是很难选择合适的学习率,太大或太小都不适合,相同的学习率不适用于所有的参数更新,另外还有一些超参量:如动量也需要仔细调整,于是出现一些自适应学习率与自适应动量的一些优化算法。
梯度下降算法对于所有参数都使用了同一个更新速率,这样有时是不恰当的,比如有些参数已经到了仅需要微调的阶段,有些参数由于对应样本少等原因,还需要较大幅度的调动。
Adagrad就是针对这一问题提出的,自适应地为各个参数分配不同学习率的算法,参数接收的更新越多(对应的梯度越大),更新越小(对应的学习速率越小),其基于梯度的历史信息来调整学习率,它适用于稀疏数据集和具有不同特征稀疏度的问题。
Adagrad算法的优点是:减少学习速率的手动调节;缺点是:分母会不断累加,这样学习速率就会收缩并最终变得非常小,需要手工设置一个全局的初始学习率。
Adadelta 算法是对 Adagrad 的改进,和 Adagrad 相比,它不是累积所有过去的梯度,而是根据渐变更新的移动窗口调整学习速率。
RMSProp优化算法是Adagrad 算法的一种改进。RMSProp算法不是像Adagrad 算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。鉴于神经网络都是非凸条件下的,RMSProp在非凸条件下结果更好,改变梯度累积为指数衰减的移动平均以丢弃遥远的过去历史。
RMSprop优化器通常是训练循环神经网络 RNN 的不错选择。
Adam是一种自适应学习率优化器,结合了动量方法和自适应学习率调整,相当于 RMSprop + Momentum。
实践表明,Adam 比其他适应性学习方法效果要好。
Adamax是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。主要用于处理稀疏梯度的问题,总的来说跟Adam效果差不了多少。
Adam可以看作是Momentum与RMSProp的结合,既然Nesterov的表现较Momentum更优,那么自然也就可以把Nesterov Momentum与RMSProp组合到一起了,这就是Nadam
引用自参考7。
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,
随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点
参考: