芯片圈变天了!英伟达推出首个CPU,狂捧Arm生态
芯东西4月13日报道,今日凌晨,一年一度影响人工智能及高性能计算技术盛会NVIDIA GTC如期而至,这是GTC大会继去年后第二次在线上举行。
NVIDIA(英伟达)创始人黄仁勋依然穿着拉风的皮衣,在自家厨房举办发布会。可以明显看到,老黄的头发更白了,也更长了。
去年NVIDIA重磅发布旗舰A100 GPU以及一系列服务器、集群、超算,轰动整个人工智能领域,如今,老黄带着一系列软硬件新品高调回归。万万没想到,这一次,全球GPU霸主NVIDIA推出了一款基于Arm的数据中心CPU!在宣布400亿美元收购Arm的6个月后,NVIDIA连发三款基于Arm IP打造的处理器,包括全球首款专为TB级加速计算而设计的CPU NVIDIA Grace、全新BlueField-3 DPU,以及业界首款1000TOPS算力的自动驾驶汽车SoC。“我们每年都会发布激动人心的新品。三类芯片,逐年飞跃,一个架构。”黄仁勋说,数据中心路线图包括CPU、GPU和DPU这三类芯片,而Grace和BlueField是其中必不可少的关键组成部分。每个芯片架构历经两年的打磨周期(周期内可能出现转变),一年专注于x86平台,另一年专注于 Arm 平台。
此外,NVIDIA还公布了与亚马逊AWS、Ampere Computing、联发科和Marvell等基于Arm的CPU平台的合作伙伴关系。在软件方面,超大规模语言模型训练与推理问答引擎Megatron、实时对话式AI平台Jarvis、AI网络安全框架Morpheus、Omniverse企业版、由GPU加速的量子电路模拟框架CuQuantum等一系列最新进展首次揭晓。显然,面向数据中心异构计算的新天地,NVIDIA正集合软硬件技术优势,打出高调的组合拳。
此次发布会令人最印象深刻的,就是NVIDIA在助推Arm生态方面不遗余力,从自研CPU、DPU、自动驾驶处理器到GPU的合作伙伴,从云、高性能计算、边缘计算到PC,无处不Arm。黄仁勋宣布的第一个重磅新品,是一款专为大规模人工智能和高性能计算应用而设计的CPU——NVIDIA Grace。绝大多数的数据中心仍将继续使用现有的CPU,而Grace主要将用于计算领域的细分市场,预计将于2023年可供货。由于超大规模的模型很难完全放进GPU内存,如果存储在系统内存,访问速度则会大大受限,这款CPU的问世主要即是为了解决这一瓶颈。
NVIDIA Grace以发明了世界上第一个编译器、被称为“计算机软件工程第一夫人”的先驱计算机科学家Grace Hopper命名,具体有3点创新进步:(1)内置下一代Arm Neoverse内核,每个CPU能在SPECrate2017_int_base基准测试中单位时间运行超过300个实例;(2)采用第四代NVIDIA NVLink,从CPU到GPU连接速度超过900GB/s,达到相当于目前服务器14倍的带宽;从CPU到CPU的速度超过600GB/s。(3)拥有最高的内存带宽,采用的新内存LPDDR5x技术,带宽是LPDDR4的两倍,能源效率提高了10倍,能提供更多计算能力。明年将有两台性能强大的AI超级计算机面世,都将采用NVIDIA Grace,据称其与NVIDIA GPU紧密结合,性能将比目前最先进的NVIDIA DGX系统(在x86 CPU上运行)高出10倍。这两台AI超算中,瑞士国家计算中心(CSCS)正在打造一个算力可达20Exaflops的系统,美国洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory)也将为其研究人员配备新AI超算。2、Bluefield-3 DPU:220亿晶体管在黄仁勋看来,负责在数据中心传输和处理数据的数据处理单元(DPU),正与CPU、GPU共同组成“未来计算的三大支柱”。NVIDIA全新BlueField-3 DPU包含220亿个晶体管,采用16个Arm A78 CPU核心、18M IOPs弹性块存储,加密速度是上一代的4倍,并完全向下兼容BlueField-2。BlueField-2能够卸载相当于30个CPU核的工作负载,而BlueField-3实现了10倍的加速计算性能提升,能够替代300个CPU核,以400Gbps的速率,对网络流量进行保护、卸载和加速。该处理器也是首款支持第五代PCIe总线并提供数据中心时间同步加速的DPU。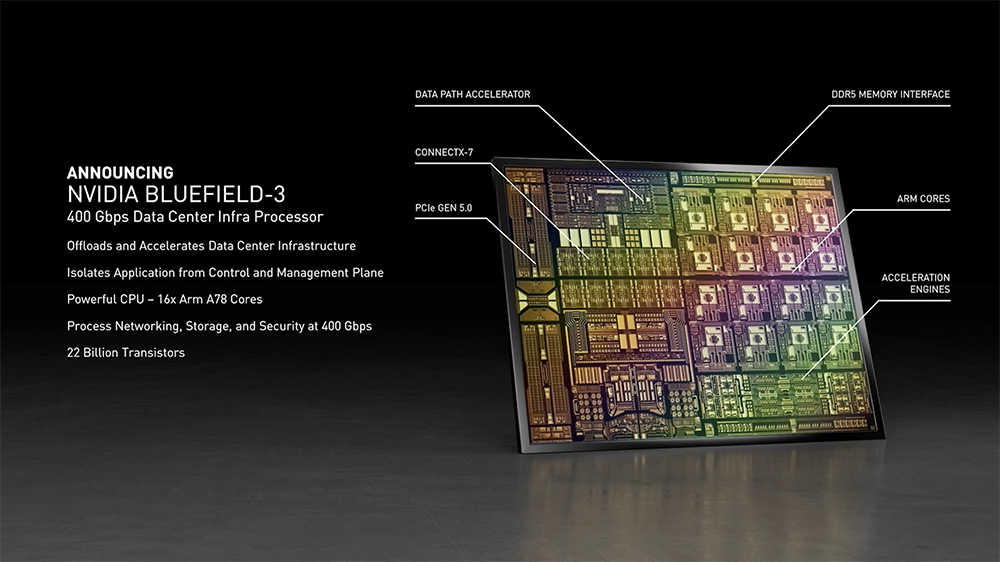
BlueField-3通过NVIDIA DOCA(集数据中心于芯片的架构)软件开发包为开发者提供一个完整、开放的软件平台,开发在BlueField DPU上开发软件定义和硬件加速的网络、存储、安全和管理等应用。DOCA已于今日发布并提供下载。新一代BlueField-3 DPU预计将于2022年第一季度发布样品,第四代BlueField DPU将包含640个晶体管,算力达1000TOPS,网络速率达800Gbps。
NVIDIA DRIVE Atlan是新一代AI自动驾驶汽车处理器,算力将达到1000TOPS,约是上一代Orin处理器的4倍,超过了绝大多数现有无人驾驶出租车的子女计算能力。
这是DRIVE平台首次集成DPU,通过Arm核为自动驾驶汽车带来数据中心级的网络,致力于应用到2025年的车型。该SoC采用下一代GPU的体系结构、新型Arm CPU内核、新深度学习和计算机视觉加速器,并内置为先进的网络、存储和安全服务的BlueField DPU,网络速度可达400Gbps。
黄仁勋夸赞说:“Atlan集NVIDIA在AI、汽车、机器人、安全和BlueField安全数据中心领域的所有技术之大成,堪称一项技术奇迹。”4、便捷式AI数据中心和DGX SuperPod双升级黄仁勋还宣布升级NVIDIA专为工作组打造的“便携式AI数据中心”NVIDIA DGX Station,以及NVIDIA专为密集型AI研发打造的AI数据中心产品NVIDIA DGX SuperPod。全新DGX Station 320G借助320GB超快速HBM2e连接至4个NVIDIA A100 GPU,内存带宽达到每秒8TB。然而,仅需将其插入普通的壁装电源插座即可使用,耗电量只有1500W。黄仁勋说,达到这种性能的CPU集群成本约为100万美元,而DGX Station仅需14.9万美元。
DGX SuperPOD使用全新80GB NVIDIA A100,将其HBM2e内存提升至90TB,实现2.2EB/s的总带宽。要实现如此的带宽,需要11000台CPU服务器,大约相当于有250个机柜的数据中心,比SuperPOD多15倍。目前它已经升级至采用NVIDIA BlueField-2,且NVIDIA如今还为该产品提供配套的NVIDIA Base Command DGX管理和编排工具。5、Aerial A100:5G+AI的新型边缘计算平台黄仁勋还提到了NVIDIA的AI-on-5G计算平台,这是一款专为边缘设计、将5G和AI相结合的新型计算平台。该平台将采用NVIDIA Aerial软件开发套件与NVIDIA BlueField-2 A100,将GPU和CPU组合成“有史以来最先进的PCIE卡。”富士通、谷歌云、Mavenir、Radisys和Wind River等合作伙伴都在开发适用于NVIDIA AI-on-5G平台的解决方案。
除了推出基于Arm的CPU外,NVIDIA还宣布一系列与Arm处理器设计商的合作进展,包括将为亚马逊AWS Graviton2 CPU提供GPU加速、为科学和AI应用开发提供支持的全新HPC开发者套件、提升边缘视频分析和安全功能、打造新一类基于Arm并搭载NVIDIA RTX GPU的新款PC等。这些举动反映出无论是市场还是NVIDIA自身,对基于Arm的解决方案的兴趣已经超出移动领域。1、NVIDIA GPU搭配亚马逊自研CPU赋能云服务2021年下半年,基于亚马逊云科学(AWS)自研服务器处理器AWS Graviton2的Amazon EC2实例将与NVIDIA GPU相结合,在云端部署。这一新组合将实现降低成本、支持更丰富的游戏串流体验、优化云上安卓游戏和人工智能推理、以更低成本提供更高的AI推理性能等优势。黄仁勋说:“我们致力于将Arm生态系统扩展到移动和嵌入式系统以外的市场,而今日宣布的新合作伙伴,正是我们迈出的第一步。”
为了更好地支持科学和AI应用开发,面向高性能计算领域,NVIDIA推出了全新HPC开发者套件。NVIDIA全新HPC开发者套件为超级计算机提供了一个高性能、高能效的平台,该平台结合了1个Ampere Altra CPU(包含80个Arm Neoverse核,运行频率高达3.3GHz)、双NVIDIA A100 GPU(每个GPU可提供312TFLOPS的FP16深度学习性能)、两个用于加速网络、存储和安全的NVIDIA BlueField-2 DPU。该开发者套件包含一套NVIDIA编译器、库和工具,可用于创建HPC和AI应用,以及将其迁移到GPU加速的Arm计算系统中,将于2021年第三季度上市,多家顶尖研究机构已率先展开部署。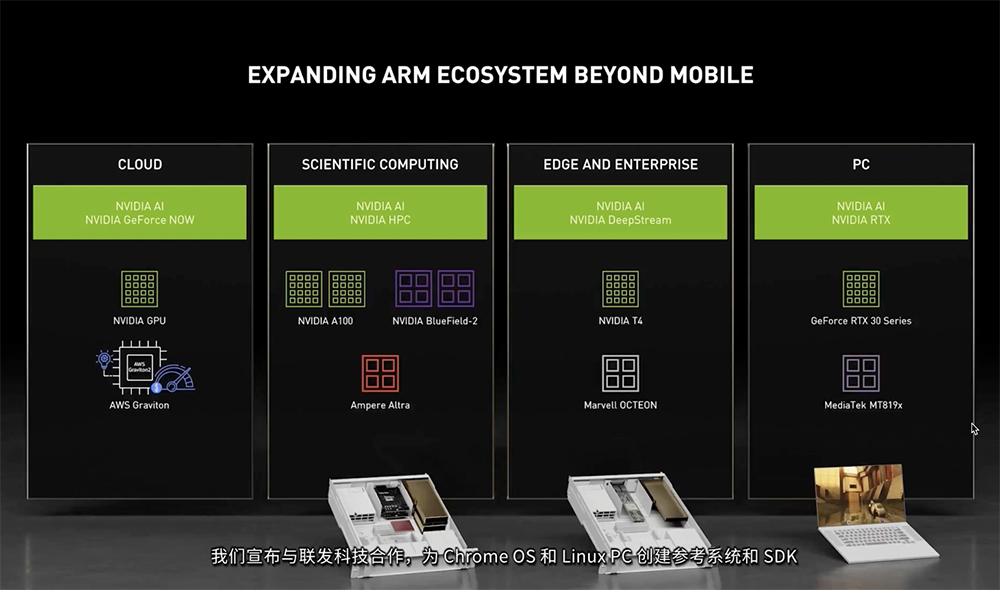
今天NVIDIA还宣布了提升边缘视频分析和安全功能、打造新一类基于Arm并搭载NVIDIA RTX GPU的新款PC等进展。在边缘计算领域,NVIDIA正扩大与Marvell的合作,将基于Arm的OCTEON DPU与GPU相结合,加速AI工作负载,实现网络优化和安全。在PC领域,NVIDIA与全球最大的基于Arm的SoC供应商之一联发科合作,共同打造一个采用Arm核与NVIDIA显卡、支持Chromium、Linux和NVIDIA SDK的参考平台,将GPU的性能及先进的AI、光线追踪图形等技术带入Arm PC平台。此外,NVIDIA也正与富士通、SiPearl等其他合作伙伴共同致力于扩展Arm生态系统。
NVIDIA在去年推出了一个机架比肩AI数据中心的AI系统DGX A100、AI算力高达700 PFLOPS的集群DGX SuperPOD、千万亿级工作组服务器DGX Station A100。面向AI应用需求,NVIDIA已经提供Megatron、Jarvis、Merlin、Maxine、Isaac、Metropolis、Clara和DRIVE、以及各种可使用TAO进行定制化的预训练模型。今天,NVIDIA进一步强化企业计算服务,不仅推出大型语言模型训练与推理问答引擎、宣布对话式AI平台最新落地进展,还展示了其量子电路模拟框架。为进一步实现AI民主化,黄仁勋发布了来自顶尖制造商的新系列NVIDIA认证系统,即大容量企业级服务器,现已通过认证。这一系统可运行NVIDIA AI Enterprise软件套件,该套件得到了全球应用最广泛的计算虚拟化平台——VMware vSphere 7的独家认证。
NVIDIA今日推出多款新系统,以扩大NVIDIA认证服务器生态系统。这些新系统配备用于主流AI和数据分析的NVIDIA A30 GPU,以及用于AI图形、虚拟工作站以及混合计算和图形工作负载的NVIDIA A10 GPU。黄仁勋发布了用于训练Transformers的超大语言模型的NVIDIA Megatron Triton推理服务器。Transformers已帮助开发者在自然语言处理领域取得了突破性进展,能够生成文档摘要、将电子邮件中的短语补充完整、对测验进行评分、生成体育赛事现场评论、甚至生成代码。
使用Megatron Triton的DGX A100能在1秒内做出响应,可同时支持16项查询,而双插座CPU服务器支持1条问询就超过了1分钟。Jarvis是一个基于NVIDIA GPU提供实时性能的灵活、多模态对话式AI服务应用框架,可帮助开发者轻松实现实时语音识别、转录、摘要、翻译、封闭式字幕、虚拟助手、聊天机器人等功能。现在,NVIDIA已经是一个生产就绪、现已可用的端到端对话式AI模型,企业可基于自身数据和特定需求对模型做进一步的微调,并使用NGC实现在云或边缘快速部署定制化语言型AI服务。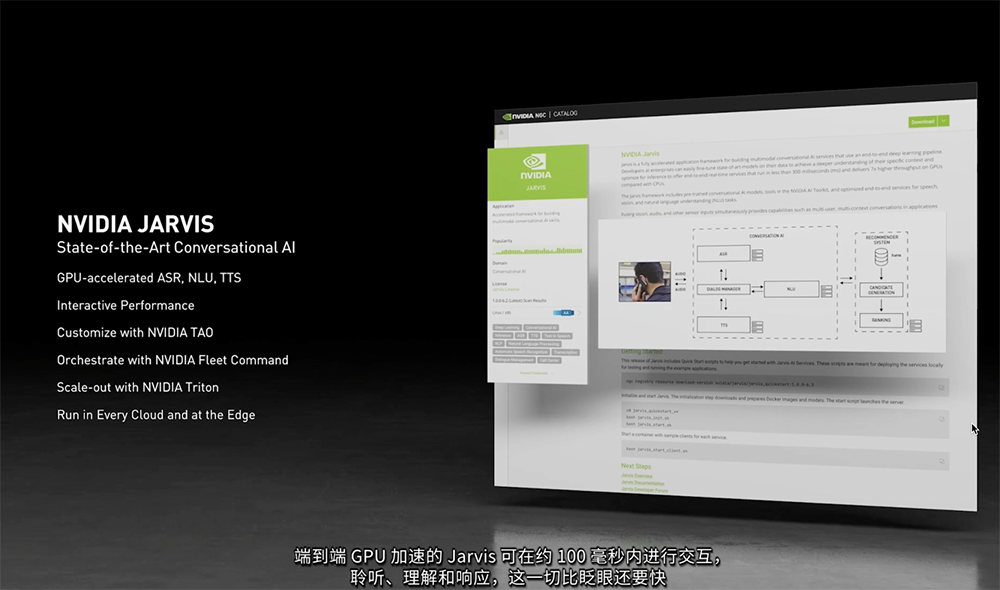
为帮助客户将自身专业知识应用于AI领域,黄仁勋还宣布推出NVIDIA TAO,其可以运用客户和合作伙伴的数据,对NVIDIA预训练模型进行微调和适配,同时保护数据隐私。为了保障现代化数据中心的安全,黄仁勋宣布推出基于NVIDIA GPU、BlueField DPU、Net-Q网络遥测软件和EGX的新型AI框架而构建的NVIDIA Morpheus数据中心安全平台,能够对完整的数据包进行实时检测、预防安全威胁,现可抢先试用。作为一个基于AI的云原生网络安全框架,NVIDIA Morpheus通过在边缘和AI技术的结合,利用实时的遥测、策略执行及操作,可以在不牺牲成本和性能的情况下分析更多的安全数据,识别、捕捉和应对以往无法识别的威胁和异常情况,如未加密敏感数据的泄露、网络钓鱼攻击和恶意软件。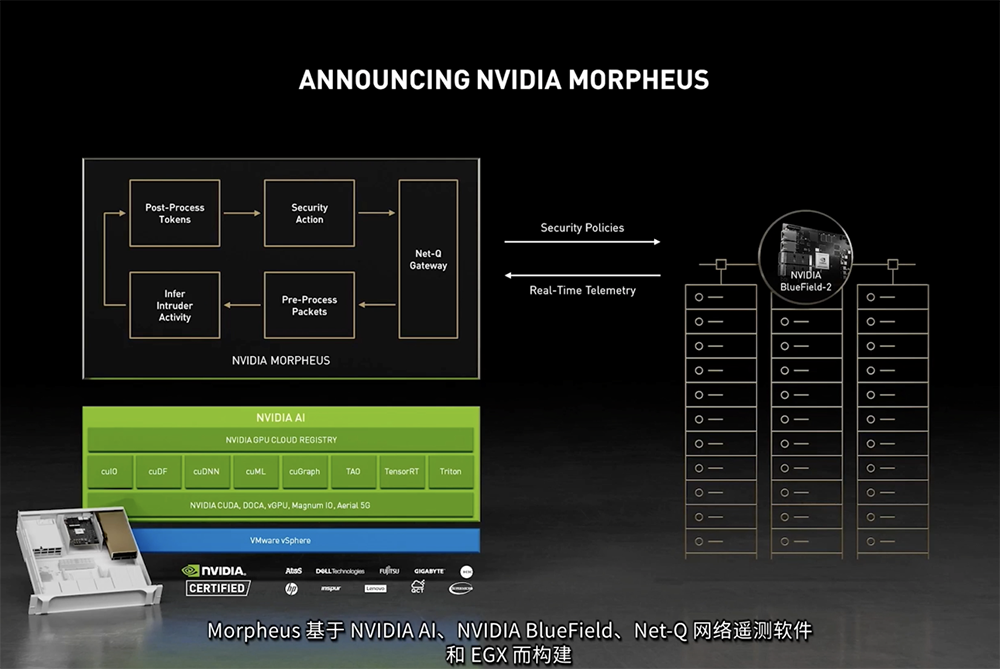
Morpheus与BlueField DPU相结合,使网络中的每个计算节点都成为边缘网络防御传感器,企业无需复制数据,也能够以线速分析每个数据包。相比之下,传统的AI安全工具通常只能采样5%左右的网络流量数据,因此威胁检测算法并非基于完整的模型。同步推出的BlueField-3可为NVIDIA Morpheus提供实时的网络可视化、网络威胁的检测与响应、以及监控、遥测和代理服务。开发者还能够在现有IP投资的基础上,使用深度学习模型来创建自己的Morpheus AI功能。为加快有赖于量子位(或量子比特,能作为单个的0或1存在,也可以同时作为二者存在)的量子计算研究,黄仁勋推出了cuQuantum,为量子电路模拟器提供加速。这是专为模拟量子电路而设计的加速库,适用于张量网络求解器和状态向量求解器,经过优化后,可以扩展到大GPU显存、多个GPU和多个DGX节点。
运行cuQuantum基准测试时,状态向量模拟在双CPU服务器上需要10天,但在DGX A100上只需2小时,DGX上的cuQuantum可以高效模拟10倍的量子位,从而助力研究人员设计出更完善的量子计算机。
自动驾驶汽车(AV,Autonomous vehicles)是NVIDIA近年来极其重视的赛道之一。除了前文提及的1000TOPS自动驾驶处理器外,此次黄仁勋还推出了Hyperion 8 AV平台,并宣布沃尔沃汽车扩大与NVIDIA的合作。NVIDIA Hyperion 8 AV平台是一个先进的数据采集、开发和测试平台,包含参考传感器、自动驾驶汽车和中央计算机、3D地面真实数据记录仪、网络以及所有必要的软件。
沃尔沃汽车从2016年开始借助高性能且高能效的NVIDIA DRIVE的算力,基于NVIDIA DRIVE Xavier,为新车型开发AI辅助驾驶功能,软件则由沃尔沃汽车旗下的自动驾驶软件开发公司Zenseact自主研发。黄仁勋说,将于2022年投产的NVIDIA自动驾驶汽车计算系统级芯片NVIDIA DRIVE Orin,旨在成为汽车的中央电脑。
而沃尔沃汽车将为新一代汽车的自动驾驶计算机配备NVIDIA DRIVE Orin。这意味着两家公司的合作深入到更多软件定义车型,首发就是将于2022年发布的新一代XC90。
黄仁勋强调说,NVIDIA是一家软件平台公司,并大力发展NVIDIA AI和将3D世界连接至共享虚拟世界的NVIDIA Omniverse。NVIDIA Omniverse是一款多GPU可扩展的云原生平台,支持建模、布局、着色、合成、渲染、动画引等一系列构建3D虚拟建模所需的功能,用于仿真、协作和自主机器训练。其特点还包括:具有高物理精度、能够充分运用RTX实时路径追踪和DLSS、可以使用NVIDIA MDL模拟材料、可以使用NVIDIA PhysX模拟物理学并且与NVIDIA AI完全集成。黄仁勋提到:“Omniverse旨在创建共享虚拟3D世界,就像尼尔·斯蒂芬森在1990年代早期的小说《雪崩》中所描述的科幻虚拟空间那样。”去年12月,NVIDIA推出了Omniverse公测版本。自公测版发布以来,建筑、游戏以及大型广告公司等合作伙伴都将Omniverse运用到其工作中。从今年夏季开始,NVIDIA将提供Omniverse企业授权许可。
黄仁勋还宣布DRIVE Sim将于今年夏季开放供业界使用。他提到Omniverse中的DRIVE数字孪生是能够与车队中每一位工程师和每一辆车互联的虚拟空间。正如Omniverse能够构建汽车生产工厂的数字孪生一样,DRIVE Sim也可用于创建自动驾驶汽车的数字孪生,并将其用于自动驾驶汽车的开发。此外,NVIDIA正与宝马合作打造一个完全采用数字化设计的未来工厂,自始至终在Omniverse中进行模拟,创建数字孪生,并让机器人与人类协同工作开展运营。
总体来看,NVIDIA今日公布的多项成果与进展,为基于Arm的解决方案带来更多可能性,NVIDIA这又打造硬件又优化软件的势头,更加彰显了其主导数据中心领域AI和HPC市场的决心,也为颇负盛名的GTC大会打出了响亮的头炮。此次GTC线上大会共超过10万人注册参会,共计将举行1600多场技术演讲。在接下来的5天内,3位图灵奖得主、12位戈登-贝尔奖得主、10位奥斯卡奖得主,以及来自微软、Arm、奥迪汽车、亚马逊、通用电气、微软等企业的领导人均将在此次科技盛会上发表演讲。从最新一系列努力来看,NVIDIA身上早已贴上远多于GPU巨头的更多标签,成为全栈计算平台。首款数据中心CPU的发布,也宣告着NVIDIA的异构计算布局再添新的关键元件,数据中心产品线集齐CPU、GPU、DPU这“未来计算的三大支柱”。NVIDIA正卯足了劲儿推进将GPU与Arm系CPU相结合的生态发展,这一切显然还只是开始。
*免责声明:以上内容仅供交和流学习之用。如有任何疑问或异议,请留言与我们联系。