设计一颗成功的内存计算SoC的关键
作者:Ron Lowman, Synopsys产品营销经理最近几年,随着AI技术的飞速发展,AI算法追求更高的性能功耗比,推动了特定硬件设计技术的发展。尤其是自2015 年以来,很多公司和风投开始大举投资专门用于 AI 的新型 SoC,促使行业龙头在 AI 硬件设计方面取得了诸多改进。例如,Intel 的 X86 处理器增加了新的指令,甚至还增加了一个单独的 NPU 引擎。Nvidia 添加了特定的 Tensor 内核,放弃了 GDDR,转而实现 HBM 技术以增加内存带宽。Google 开发了专门用于 AI 算法的特定 ASIC TPU(Tensor 处理单元,图 1)。但是,即使这些架构不断改进,投资者仍然希望有更具创新性的企业能够开发出颠覆性的 AI 技术。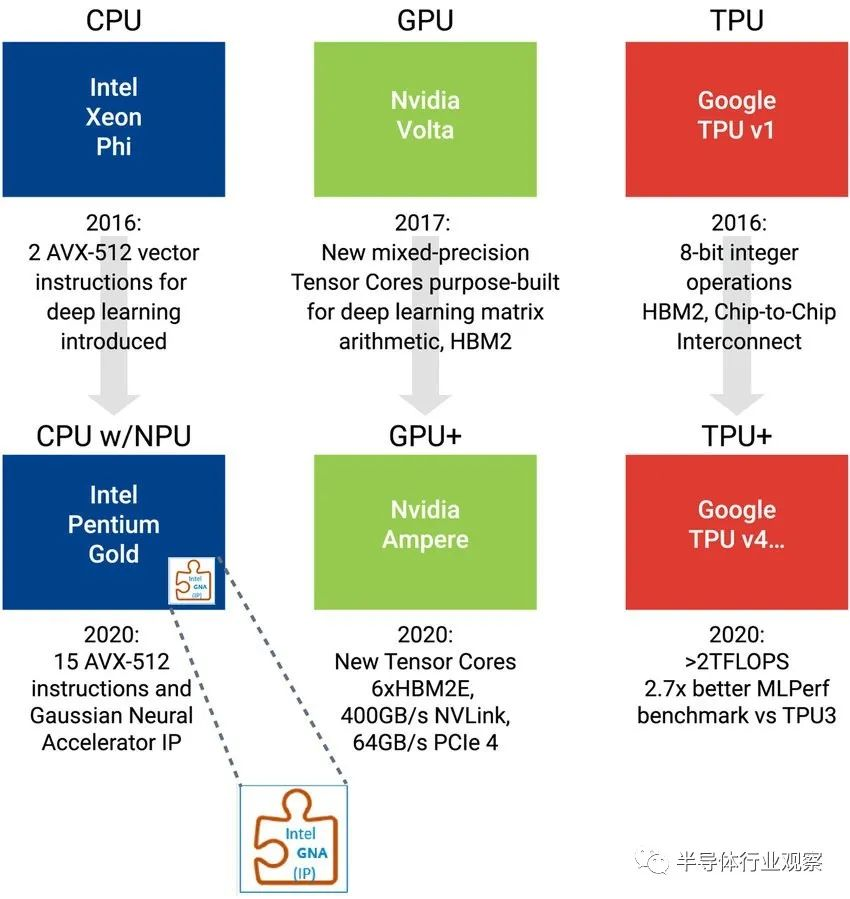
图 1:Intel、Nvidia 和 Google 正在引入新的硬件架构,以提高 AI 应用的性能功耗比目前产生的数据量呈指数级增长,而 AI 是解决复杂性问题的关键技术;
使用现有架构(尤其是边缘)运行 AI 算法的功耗和时间成本仍然过高;
AI 计算引擎的并行化达到芯片尺寸极限,促使这些系统扩展为多个芯片,而这种扩展仅在云或边缘云数据中心领域较为实用。
这些挑战促使设计人员不断探索新的硬件架构,而内存计算则被视为其中最有前景的硬件创新之一,因为它可以带来极大的改变。
首先,让我们来看看什么是内存计算?内存计算是将内存设计在硬件处理元件旁边或内部的方式。内存计算会利用寄存器文件、处理器内的内存,或者将 SRAM 或新内存技术的阵列转换为寄存器文件或计算引擎本身。对于半导体而言,内存计算的基本要素可能会大幅降低 AI 成本,缩短计算时间和降低功耗。内存计算的定义包含了硬件和软件两部分。从软件的角度来看,内存计算是指在本地存储中运行的处理分析,实际上,软件充分利用了离计算较近的内存;从硬件的角度来看,“内存”可以理解为本地系统中的 DRAM、SRAM、NAND Flash和其他类型的内存,而不是通过联网软件基础架构获取数据。通过软件优化提高本地内存的利用率,这一做法为行业带来了巨大的进步,然而通过适当的硬件优化,内存计算的效率甚至能达到现行计算的 1000 多倍,更加具有创新性。
除了活跃于内存计算领域的初创企业外,许多行业龙头也在私下应用该项技术。目前行业探索 AI 计算加速的路径主要包括如下几种:各家企业都在探索这些提高性能的方法,有些已经初见成效。而内存计算设计可以在这些方法的基础上,辅以其他的开发技术,大幅度提高效率。此外,内存技术的发展也在协助解决内存计算的挑战。与传统的 SRAM 相比,MRAM、ReRAM 等新型内存技术可提供更高的密度和非易失性,因此前景广阔。对 SRAM 的改进可提高计算和片上内存的利用率——这是 AI SoC 设计人员面临的最关键的设计挑战之一(图 2),他们需要专门为 AI 数据的移动和计算设计内存子系统。
图 2:AI SoC 具有极其密集的计算和数据移动,这会影响延迟、面积和性能AI SoC设计的关键挑战与存储系统的MAC数量、需要存储的系数两者有关。对于 ResNet-50 而言,需要超过 23M 的权重,计算到 35 亿 MAC 和 105B 的内存访问。并非所有处理都在同时运行,因此最大激活值的大小可能是内存子系统的关键瓶颈。控制工程师知道,将瓶颈设计作为执行成本最为昂贵的功能,从而提高效率。因此,系统设计需要确保其内存计算架构能够有效地处理最大的激活系数层。满足这些要求需要大量的片上内存和多层的密集计算。目前业界正在开发内存设计的独特技术,以消减延迟、系数体量以及必须在 SoC 周围处理的数据量。内存计算不仅仅是 AI 算法的神奇解决方案,它有不同的实现方式,而且还在通过逐步创新得以发展。寄存器文件和缓存的实现已有数十年之久,过去几年近内存计算作为一种改进的技术,已应用于新的SoC中。AI 算法需要数百万甚至数十亿的系数和乘法累加(MAC)。为了高效地执行这些 MAC,工程师在 SoC 中设计了用于一系列 MAC 的自定义本地 SRAM,其唯一用途是执行 AI 模型数学,即矩阵/张量数学。为一组 MAC 集成专门的本地 SRAM 以执行 AI 模型数学就是近内存计算的概念。在近内存计算中,本地SRAM为了存储其指定MAC单元所需的权重和激活而进行了优化。内存计算发展的下一步是模拟计算。模拟计算能够实现更多并行,更接近人脑的效率。模拟系统并行运行 MAC 和内存,就系统效率的提升幅度而言,甚至远远超过仅靠近内存计算方式得到的效率提升。传统的 SRAM 可以作为内存模拟计算实现的基础,而新思科技已针对这一用途提供了定制化服务。用于内存计算的 DesignWare IP 解决方案
新思科技为客户提供广泛的 IP 选项以实现内存计算。他们将内存编译器特别针对密度或漏电功耗进行了优化,可用于为近内存实现开发本地的SRAM,就像MAC这种功能有时被添加到芯片(实例化)数千次。MAC 可以利用新思科技基础内核的一组原始数学函数,其中包括点积(一种常见的 AI 函数)等灵活函数。
随着 AI 技术的普及,多端口内存在设计中更加常见。新思科技 DesignWare 多端口内存 IP 支持多达 8 个输入或 8 个输出,提高了计算架构内的并行性。此外,新思科技还开发了一种专利电路,用来支持内存计算创新性发展。图 3 中所示的 Word All Zero 功能基本上消除了要处理的零。Word All Zero 功能显著减少了计算量,并可将芯片内数据移动的功耗降低多达 60%。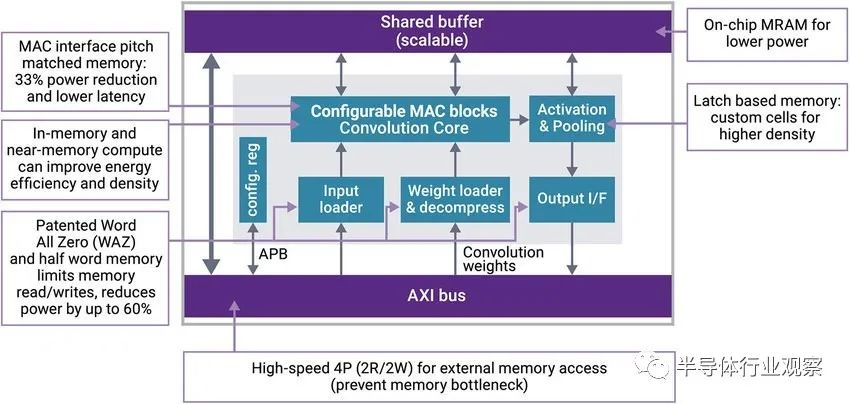
图 3:除了 Word All Zero 功能外,新思科技DesignWare 嵌入式内存 IP 还提供多种特性,以解决功耗、面积和延迟挑战
内存计算的未来发展还有待观察。然而,具有新型内存、创新电路和创造性设计师的技术及概念的实现,无疑是一项激动人心的工程。
*免责声明:以上内容仅供交和流学习之用。如有任何疑问或异议,请留言与我们联系。