喜欢4次
在完成神经网络量化后,需要将神经网络部署到硬件加速器上。首先需要将 所有权重数据以及输入数据导入到存储器内。
在仿真环境下,可将其存于一个文 件,并在 Verilog 代码中通过 readmemh 函数读取。接下来需要使用扩展指令,完成神经网络的部署,此处仅对第一层卷积+池化的部署进行说明,其余层与之类似。
1.使用 Custom_Dtrans 指令,将权重数据、输入数据导入硬件加速器内。对于权重,需要将 6 个卷积核数据分别从存储器导入硬件加速器内,如下所示:

代码中 DMA_RAM 代表发送端为存储器,weight_RAM 代表接收端为权重 数据存储器,9 代表传输数据的个数为 9(卷积核大小为 3*3,3*3=9)。 对于输入数据其导入过程代码如下:

代码中 DMA_RAM 代表发送端为存储器;data_RAM 代表接收端为输入存 储器;131072 代表存储器发送数据的起始地址,即输入数据的存储位置;28*28 代表输入数据的长度为 28*28,对应于手写数字识别输入图像的大小。 2.使用 Custom_Ldata_Param、Custom_Lweight_Param、Custom_Pooling _Param 指令将相关参数传入硬件加速器内。 对于参数设置如下所示:
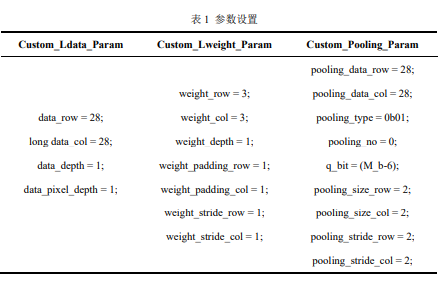
由于缩放尺寸也经过了量化,并且量化结果对于第一层而言是5 ∗ 2^(−12), 因此 M_a 设定为 5,M_b 设定为 12。由于在 pooling 模块中可以进行量化操作, 所以 q_bit 可以进行相关设计进行初步量化。为了保证计算精度,仅在 pooling 模 块内进行部分量化,另外一部分在 RISC-V 主处理器内完成。
3.使用 Custom_run 指令执行计算操作。 在使用 Custom_run 指令执行计算操作之前需要使用 Custom_clr 指令将执 行状态清空,清空方式采取全部清空模式,故 Custom_clr 指令对应输入参数为 0b11。 18 对于第一层卷积+池化,需要使用卷积、激活、池化功能,因此,Custom_run 指令的第一个输入参数 param1 需要设定为 0b11,第二个输入参数 param2 需要 设定为 0b100。
4.使用 custom_soutput 将计算完成的数据取出 对于 6 个卷积核的计算结果,需要分别取出结果数据到 RISC-V 主处理器内, 便于做下一步的数据处理。其代码部分如下:

代码中 output 数组用于接收计算结果,sel_temp 用于选择接收第几个卷积核 的计算结果,output_length 代表接收数据的长度。 5.在 RISC-V 主处理器内对数据进行进一步量化。 对 output 数组内数据首先乘以 M_a,然后移位 6 位。对于超出 127 的结果 数据需要将其设定为 127,代码如下所示:
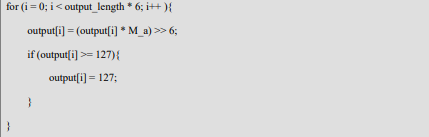
6.将量化完成后的结果传回存储器内。 使用 Custom_Dwrite 指令将量化后的结果数据导入存储器内。代码如下所 示:

代码中 output 即完成量化后的结果数据。14*14*6 代表需要传输的数据量,
对应于池化后的数据量。131072 代表在存储器内存储数据的起始地址