喜欢2次
团队:站着撸代码
大家好,本团队此次分享的内容为可实现数据全复用高性能池化层设计思路,核心部分主要由以下3个部分组成;
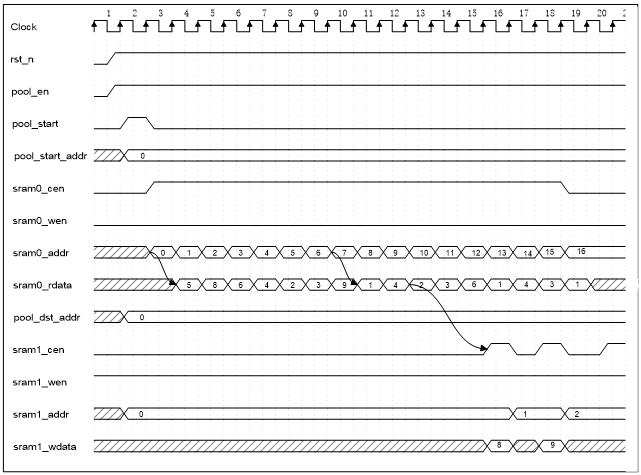
1.SRAM读取模块;——池化使用的存储为SRAM
基于SRAM读与写时序,约束池化模块读与写时序。读数据时,输入读取地址后,于下一时钟SRAM输出该地址读数据;写数据时,地址与数据同步输入SRAM。
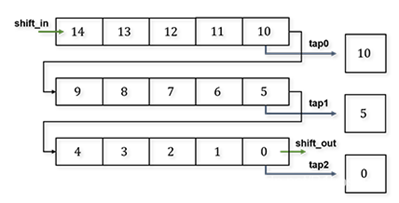
2.SHIFT_RAM模块;
下图为SHIFT_RAM原理图,借鉴行缓存器的原理,填满后输出行首,使用时根据输入实际图像大小与核大小使用对应容量,eg.map_max=64,fliter_max=8,则需64*8的大小。
3.数据处理模块
基于以上SHIFT_RAM输出的数据,数据处理模块主要实现两个功能,一是通过cnt、cnt_col、cnt_stride_col、cnt_stride_row分别记录输入的总像素、当前窗口所在列、当前窗口所在步长间隔,用于数据有效性判断。二是使用三级流水线处理数据,其中max pool使用比较、缓存、比较,分别比较tap数据、缓存中间数据、比较中间数据。三级流水线的输出分别存放在maxval、data_middle[i]和max_value三个中间结果中;average pool使用累加、缓存、累加并相除,分别累加tap数据、缓存中间数据、累加中间数据并做除法得平均。三级流水线的输出方别放在sum_data、data_middle[i]和sum_data_middle与ave_value四个中间结果中。其中比较与除法均使用组合逻辑实现。
下图为实现比较结构图,当核尺寸最大为8时,SHIFT_RAM每次输出8个行首数据,将这8个数据通过比较模块按下图方式比较出data_r,再基于data_r与核大小进一步比较大小。例如核尺寸为2时,data_r即为比较结果,核尺寸为4时,则对data_1与data_3进行一次比较即为比较结果,以此类推。

实现以上部分,可实现池化数据的全复用,无需多次读取数据,且池化时间短,性能高。